Data Sources and Data Acquisition
Data are the foundation of predictive modelling. Before a predictive model can be built, relevant data need to be collected and examined. Significant challenges are often encountered during these processes, such as:
- Time-consuming data gathering
- Legal barriers and permissions to use data
- Potential mismatches between expectations and the actual quality or completeness of the data
- Complexities when integrating datasets that contain varying measures, naming conventions, and different levels of granularity
The topics in this module provide insight into what data is and how to collect it from official data providers.
Throughout this module, the following topics will be covered:
- Data and Metadata
- Coding and Classification Systems
- Health Data Providers in Denmark
- Exercises
Data, Metadata, and Annotations
When working with data, it is useful to differentiate between data and metadata. Data are the raw facts and measurements collected (e.g. patient blood pressure, lab test results, or imaging data), while metadata is “data about the data” (e.g. units or measurement methods). That is, metadata provides additional context and interpretation. For example, if a table containing information about blood pressure measurements (e.g., type of measures and measurement values) is data, then metadata would consist of descriptive information about that table. This metadata might specify that ‘Measurement values’ is a numerical value and ‘Measurement’ is text. The descriptive details in the metadata are frequently within the data structure itself. However, it can be presented as a separate table providing details about each column of the data table. A basic example of this can be seen in the illustration below:
Example of raw blood pressure data:
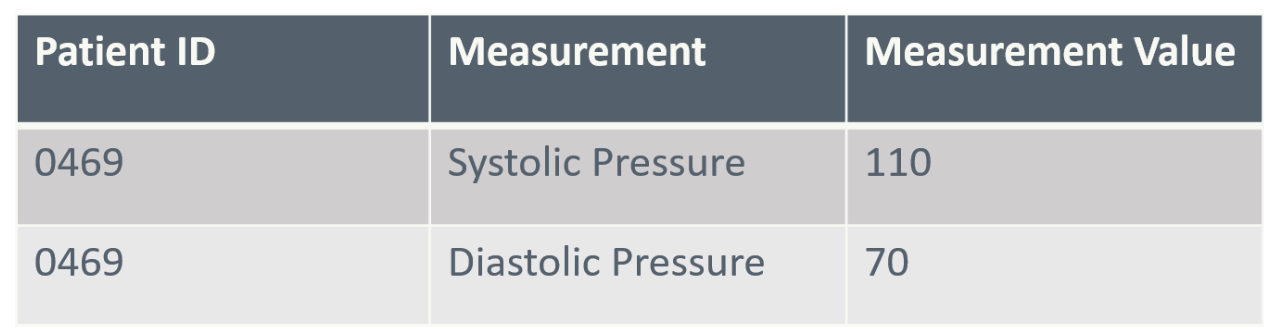
Example of metadata for the blood pressure data:

Description of the data
A critical requirement for performing any kind of modelling involving data is to have a deep understanding of the data. To be able to provide a detailed description of the data is an efficient approach to understand the background, implications, and meaning of the data. Knowing who collected the data at which time can provide some insight of the standards at the given time. Understanding the meaning of the columns, what the values represent, the population in the data, and the data distribution is the foundation for conducting meaningful modelling of the data.
Coding and Classification Systems
To manage and analyse large amounts of health data, standardised coding and classification systems are essential. These systems simplify complex medical information (such as diagnoses, procedures, and lab results) and these systems are are widely implemented across health registries.
A central Danish health data classification system is the Sundhedsvæsenets Klassifikationssystem (SKS), which is managed by The Danish Health Data Authority. SKS is the national standard used throughout the Danish healthcare system.
The SKS uses the World Health Organisation’s International Classification of Diseases, 10th Revision (ICD-10) for diagnostic data, thereby ensuring that Danish data is aligned with international standards.
All Danish diagnostic SKS code data can be searched through an open database, to either find a diagnosis by code or a code by diagnosis, as illustrated in Figure 1.
Figure 1: SKS browser for code description. Screenshot from medinfo.dk
For specific types of data, such as clinical laboratory data, more specialised terminologies are required. This type of data also has a widely adopted standard called Nomenclature for Properties and Units (NPU) terminology. The NPU provides unique identification codes for each type of laboratory analysis, e.g. blood tests, and are adopted in laboratory databases in Denmark, such as LABKA.
SNOMED CT (Systematised Nomenclature of Medicine Clinical Terms) is the most comprehensive multilingual clinical terminology in the world. The core purpose is to serve as an ontology (a “Model of Meaning”) for clinical information. Enabling a common language to exchange information about diagnosis, procedures, medicine, and much more. SNOMED CT is a terminology designed to be logical, by having nested structures for all the information. It is designed to be flexible, as different variations of SNOMED CT for specific applications exist. Examples of such is the Danish pathology database Patobank, which adds letters to the SNOMED CT code to provide additional coding axes, such as structure, location, and cause, for the cancer data. See more on Patobank.dk. Having standardised codes for medical information is one of the main components of being able to have functional interoperability between units that share medical information.
For further information, please see this book: Benson, Tim, and Grahame Grieve. (2021) “Principles of health interoperability.”
Health Data Providers in Denmark
Denmark has a unique system of nationwide health registries that collect data on diseases, treatment, and outcomes. These comprehensive databases form a valuable foundation for developing predictive models and research in general. The registries are administered by major public organisations in Denmark, which act as the official data controllers responsible for safeguarding information due to its person-sensitive nature. Below follows two of the major data controllers of healthcare data in Denmark.
The Danish Health Data Authority is one of Denmark’s primary entities for managing and providing access to extensive healthcare data. It maintains a wide array of national health registers, such as:
- The Danish Register of Causes of Death
- The Danish National Patient Register
- The Danish National Prescription Registry
- The Danish Pathology Register
- The Clinical Laboratory Information System Register
The Danish Healthcare Quality Institute is an organization that collaborates across the Danish healthcare sector, often focusing on areas such as clinical guidelines, evaluations, and clinical quality registries. This institute facilitates access to numerous health-related databases, including over 40 clinical quality databases, such as:
- Danish Head and Neck Cancer Database
- Danish Prostate Cancer Database
- Danish Diabetic Database
- Danish Heart Registry
- Danish Lymphoma Database
Exercise
Based on the module regarding Danish health registries and data acquisition, please choose the correct option for the following questions:
- Ulcerative colitis
- Crohn’s disease
- Pancreatitis
- Yes
- No
- ICD-10 diagnosis codes from hospital contacts
- SNOMED-coded pathology results
- NPU-coded laboratory test results
- Free-text clinical notes from hospitals
To proceed to the next section of the course, please click the button below.