Implementation
Up to this point, we have focused on how to develop a dynamic risk prediction model, yet this is only half the challenge. The real impact happens when these models are seamlessly integrated into clinical workflows, connected to real-world data sources, and delivered to clinicians in real time.
This section introduces the practical side of deploying prediction models in health care, which is made possible by established data exchange standards, such as FHIR Fast Healthcare Interoperability Resources (FHIR). This standard streamlines the interaction with healthcare data globally. FHIR was briefly introduced under Data Sources and Data Acquisition and will be further elaborated here.
This section will cover:
- Hosting and access to data
- FHIR
- Validation
- Exercises
Hosting and access to data
Healthcare professionals generate and record much of the data in healthcare. However, they cannot manage it on their own. It must be stored digitally in an infrastructure that is easily accessible, secure, and can store all data from every health care professional at a regional, national, or even international level.
Through this infrastructure, information about patients, such as diagnoses and treatments, can be transferred, stored, and reused by researchers. The infrastructure also provides services support for decision-making processes.
Sharing of services are enabled through a network of servers. The term server refers to the computers providing the services. Network types includes Local Area Networks (LAN), which are clusters of connected devices. A LAN can be anything from a household with a Wi-Fi router to a university or hospital having a local, closed network where data can only be shared within that specific network. The other network type is the Wide Area Network (WAN), which is the global network that connects all the LAN networks, making data sharing among a wide range of devices possible. Resources, such as database servers with information about Danish residents, are primarily accessed through these broader networks.
The LAN and WAN networks are connected by physical devices, such as routers or access points, which enable data retrieval and transmission to the intended locations within the networks. Through these mechanisms, the sharing of resources and information is securely facilitated.
Servers typically operate within a client-server architecture, a fundamental model of network interaction. The client-to-server architecture is illustrated in Figure 1:
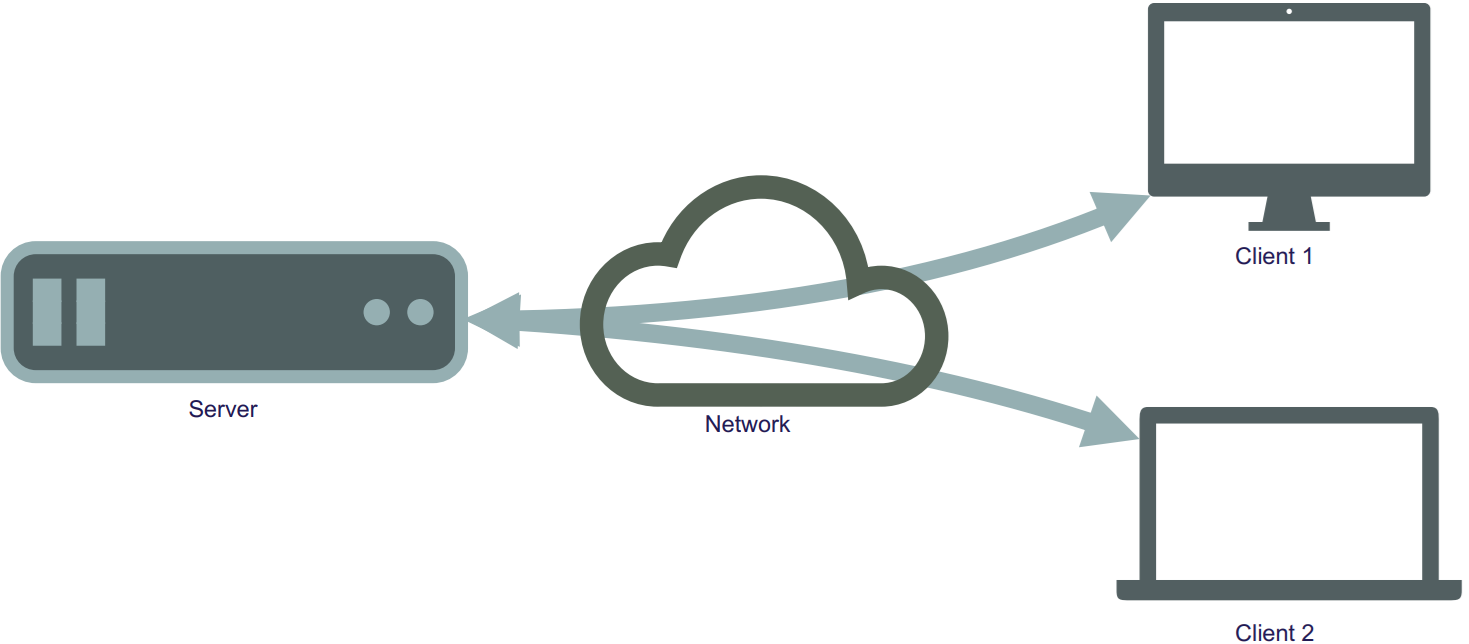
Figure 1: Illustration of the interaction of servers and clients through networks.
There exist different types of servers, such as those for websites, search engines, email services, and databases. A database server is a type of server through which information is managed for easy access, management, and updating of databases. A database is composed of physical storage and software that enable the insertion, retrieval, and management of data from storage.
To generate a new risk prediction from a trained model, the required raw input data must be retrieved, possibly preprocessed, and then made available to the model. This data will be placed in a database hosted on a database server.
The database server can be linked to other servers where the predictive models are hosted. Easy and secure interaction between data, models, and the user interface, which displays predicted risk and auxiliary information to the user, is facilitated by this network of servers.
This process is illustrated in Figure 2.
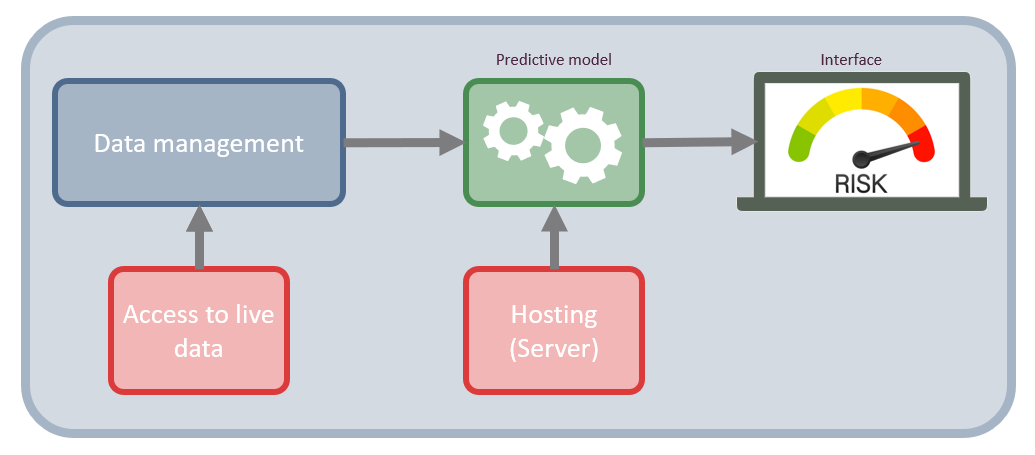
Figure 2: Network infrastructure of a risk assessment tool for clinicians. It shows how data is accessed directly at the data sources and how they are processed in the data management component, then feed into the predictive model which is hosted on a server. The result of the model is then displayed on an interface on a local computer.
Figure 2 shows the structure and the components necessary to build a basic predictive modelling system. The two main component are the data management component, which is what handle the data acquisition and preprocessing. The other component is the predictive modelling component, which calculates the risk score. The two main components are supported with access to live data and hosting of the system.
Access to data is typically not direct, but rather goes via an Application Programming Interface (API). An API a standardized set of rules and protocols that allows two separate software applications to communicate with each other. Because APIs provide a structured way for systems to interact, this approach is effective for establishing automated tasks using a cron job, which is a scheduled task that is executed at a predetermined time or interval. For example, such jobs could involve triggering an API to update the database at midnight with all the blood tests collected throughout the day. The display on the app or webpage would then function through an API communicating with the backend system to securely read the appropriate data for the given tasks.
Each API consists of a set of rules and a language that dictate how a client communicates with a server. These rules, known as the API protocol or architecture, specifies the applicable data formats, commands and overall behavior of the API. Many different API protocols and architectures exist, but the Representational State Transfer (REST) architectural style is typically used. REST is considered versatile, as no single message format is enforced by the style itself for the messages that can be handled. For REST interactions, a Uniform Resource Locator (URL) is used as the endpoint, and HyperText Transfer Protocol (HTTP) verbs (GET, POST, PATCH, PUT, and DELETE) are employed to perform operations such as resource creation, reading, updating, and deletion (CRUD). It is useful because it facilitates the exchange of data between servers and clients. An API that follows this style is referred to as a RESTful API.
When a client wants to retrieve a specific dataset from a database, they formulate a request that specifies exactly what they need, for instance, the target dataset, specific variables, or a particular time period. The data is then pulled from a server and provided to the client. With a RESTful API, this request is formulated as a specific URL address and follows the HTTP protocol.
An example of using a RESTful API could be to get data on a certain patient from a database. In this case, there must be a server address, the server needs to have a patient list, and the patients need to have some identifiers, like an ID number. If the server requirements are satisfied. The GET action can be employed:
GET(https://server.com/Patient/123)
This call would return a structured output, such as JSON or XML of the available patient data for the patient with ID 123. This output could look like the following:
{ "id": "123", "name": "Hans Hansen", "age": "56", "Gender": "Male" }
An example of a standard that leverages the principles of the RESTful API and is widely utilized in the healthcare sector is FHIR.
For further information about API and API design, see this book: Lauret, A. (2025)
FHIR
FHIR is a global standard published by HL7 for formatting and sharing health data. Built on a RESTful architecture, FHIR allows for standardized data access, which is beneficial for interoperability between different systems. Within this framework, health information is organized into discrete, standardized units called “resources”, such as a patient profile, a diagnostic report, or a medication.
To improve usability, these FHIR resources are made available in both human-readable and machine-readable formats. While the RESTful architecture enables the actual access to real-time data, this standardized structure ensures that developers can easily interpret the information, and software applications can reliably process it.
In Denmark, FHIR has been implemented in electronic health record systems, such as Columna CIS and Columna Cura, at hospitals and municipalities. The number of implemented systems is expected to increase as more projects adopt FHIR to enhance data sharing.
FHIR is used to access real-time data from various sources, which can then inform prediction models. FHIR reduces the time and effort needed for data collection and preparation, facilitating clinical implementation. The pipeline in Figure 2 is updated with FHIR implementation in Figure 3:
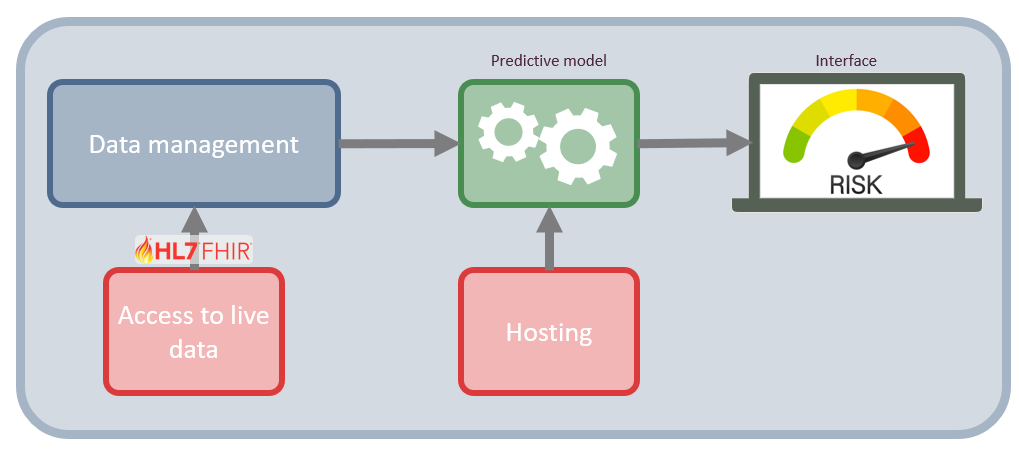
Figure 3: Network architecture of a risk assessment tool including FHIR interaction.
The FHIR standard is organized into modules, which categories related health data structures (resources) based on their clinical or administrative purpose. For instance, the FHIR administration module covers most of the basic live data relevant to medical research, and the remaining info can be obtained using various other FHIR modules.
Considering the example of predicting 30-day mortality in lung cancer from the introduction of the course. Relevant live data in a FHIR format looks as follows:
Patient: the baseline information about the person (e.g., sex and age), along with something unique to identify them by (e.g., CPR number in Denmark).
EpisodeOfCare: Information about long-term care episodes, along with diagnoses and a time frame of when they were in care. Such as cancer diagnosis, comorbidities, and contacts.
Observation: Anything measured, such as weight, the results of biochemical tests (Albumin, LDH), and BMI.
Procedure: Drug administrations, surgeries.
The first two points are from the administration module, the third from the diagnostic module, and the final from the clinical module.
Technical validation of the implementation
Technical validation of the implementation is a process of ensuring the functionality and the quality of the software infrastructure surrounding the dynamic risk prediction model in production. In this context, the ‘system’ is defined as the complete technical infrastructure, including the servers, data pipeline, and API connections.
In terms of technical validation of the implementation, there are three main types: prospective, concurrent, and retrospective.
The prospective technical validation is an important validation type, as it validates that the system performs as intended, based on its protocols, after the system is used in practice. There is an emphasis on verifying that the technical implementation functions, separate from the clinical validation of the prediction model as discussed in earlier in the course.
The validation process typically follows a systematic approach, starting with the process design, then going through the installation, operational, and performance qualifications. It is typically required that the system pass the validation checks before it is deployed.
Next is the concurrent validation, which is relevant when the system has been implemented and used. It serves to check whether the system is still in control and is compliant. This type of validation is typically used when something related to the system is changed, such as the introduction of new data (e.g., another hospital’s data is made available and is used in the model) or a change of equipment. As it is concurrent, any deviations found can be corrected on an ongoing basis.
Finally, the retrospective validation, which uses historical data and records to validate the system. The main reason to use this type of validation is if no prospective validation was performed before launching, and thus, no evidence for the system’s efficiency exists.
For further information, please see this book: Benson, Tim, and Grahame, Grieve. (2021).
Exercises
Before You Begin: Environment Setup
In a real-world scenario, you would connect to a remote hospital server via the internet using HTTP protocols. To save you the hassle of setting up API authentication, VPNs, and security clearances for this exercise, there are provided a simulated ’mock server (the requests_fhir scripts) for both R and Python.
You will construct URLs and pass them to this script exactly as if you were communicating with a real web server, but it will process the data locally on your machine.
File Setup:
Because the mock server acts as a stand-in for a real database, it needs to follow a exact folder structure. the folder structure should look as follows: 1. Create a main folder for this exercise on your computer. 2. Download the mock server script (requests_fhir.py or request_fhir.R) and place it in this main folder. 3. Create a subfolder named exactly data inside your main folder. 4. Download the raw exercise data and place all the CSV files into this data subfolder.
Your folder should look like this:
my_exercise_folder/
├── requests_fhir.py
├── requests_fhir.R
└── data/
├── baseline_data.csv
├── blood_data.csv
├── diag_data.csv
├── quest_data.csv
├── snomed.csv
├── treat_data.csv
└── visit_date.csvPlease note, that when a single patient is requested from a FHIR server, it returns a single “Patient” object. However, when you query a list of patients or multiple observations, FHIR groups them into a Bundle. When the JSON response is received, there is a extra step of navigating into the Bundle (in this exercise, under a key called entry or resource) to extract the individual records.
Exercise 1: List patients using the GET method
The goal of this exercise is to fetch a list of all the patients from the mock FHIR server and display their information. This is a realistic experience of querying a secure database to pull a cohort of patients.
The steps are as follows:
- Define the base URL for the mock server:
https://test/fhir
Python hint: Import the requests_fhir.py script as request and the json library:
requests_fhir.py
import requests_fhir as request
import json
import pandas as pd
BASE_URL = 'https://test/fhir'R hint: Source the request_fhir.R script:
request_fhir.R
source("request_fhir.R")
library(jsonlite)
library(dplyr)
BASE_URL <- "https://test/fhir"- Construct the full URL to access the patient resource. Following RESTful principles, this is achieved by appending
/Patientto the base URL.
Python hint: Use an f-string to create the URL:
patients_url = f'{BASE_URL}/Patient'R hint: Construct the URL by using paste0():
patients_url <- paste0(BASE_URL, "/Patient")- Make the request using the provided
get()method (get_r()in R) with your URL.
Python hint
response = request.get(patients_url)R hint
response <- get_r(patients_url)- Parse the JSON object to extract the list of patient entries.
Python hint: Use json.loads() to parse the object. It is highly recommended to print your JSON object (e.g., print(json.dumps(parsed_data, indent=2))) to visually inspect the nested Bundle structure:
parsed_data = json.loads(response._content)R hint: Use jsonlite::fromJSON() to parse the data:
parsed_data <- fromJSON(response$content)- Extract the variables and build a dataframe.
- Iterate through the nested entries to pull out the relevant patient data and organize it into a structured dataframe.
Python hints:
- The patient data is nested in the JSON structure under
['entry']. Iterate through this list to access the['resource']for each patient. - Create an empty list, append the extracted patient dictionaries to it, and then convert the list into a Pandas DataFrame.
Python Example code
patients = []
for entry in parsed_data['entry']:
resource = entry['resource']
patients.append({
'id': resource['id'],
'gender': resource['gender'],
'birthDate': resource['birthDate']
})
patients_df = pd.DataFrame(patients)
print(patients_df)R hints:
- The parsed data is a list containing the Bundle. The patient information is nested inside
parsed_data$entry$resource. - You can use
dplyr::bind_rows()or functions from thepurrrpackage to flatten this nested structure into a clean dataframe.
R Example code
entries <- parsed_data$entry$resource
patients_df <- data.frame(
id = entries$id,
gender = entries$gender,
birthDate = entries$birthDate
)
print(patients_df)Exercise 2: Find the code for a specific observation
In medical databases, clinical concepts are standardized using coding systems (like SNOMED CT). To extract information about a patient’s cholesterol, you first need to know the correct system code.
Task: Look into the snomed.csv file (located in your data folder) and search for labels like ‘ldl’ or ‘chol’ to find the standardized code for cholesterol. Keep this code, as it will be utilized for the next exercise.
This exercise can be completed with R and Python. But the files can also be inspected manually.
Exercise 3: Get measurements of cholesterol for a patient and plot them over time
This exercise will combine the two previous exercises by fetching a single individual’s data and plotting their cholesterol level over time.
Query Parameters: To filter data in a REST API, there is a “query parameters” at the end of your URL. You start the filter with a question mark ?, assign a value with =, and chain multiple filters together using an ampersand &.
The URL string should somewhat like this:
https://test/fhir/Observation?patient=123&code=456The steps are as follows:
- Select a patient: Choose a specific
patient_idfrom the dataframe you created in Exercise 1. - Select the code: Use the cholesterol code you found in Exercise 2.
- Construct the URL: Query the Observation resource and filter by your patient and code. The format of the URL will be:
.../Observation?patient={patient_id}&code={chol_code} - Make the request: Send a GET request to the mock server using this newly constructed URL (similar as to exercise 5.1).
- Parse and Extract: Parse the JSON Bundle. Extract the cholesterol values and their corresponding dates (recorded under
effectiveDateTime).
Python hint
dates = []
values = []
for entry in parsed_obs['entry']:
resource = entry['resource']
dates.append(resource['effectiveDateTime'])
values.append(float(resource['valueQuantity']['value']))
obs_df = pd.DataFrame({'date': pd.to_datetime(dates), 'cholesterol': values})
print(obs_df)R hint
entries <- parsed_obs$entry$resource
obs_df <- data.frame(
date = as.Date(entries$effectiveDateTime),
cholesterol = as.numeric(entries$valueQuantity$value)
)
print(obs_df)- Visualize: Plot the extracted cholesterol values over time.