Data policy
With respect to person-specific datasets
A priority of the Sandbox is to guide health data science learning using real-world-similar datasets. A major component is addressing how to analyze and leverage person-specific data, such as electronic health records, without invading personal privacy or straying from GDPR guidelines on sensitive data use. We are therefore focused on using either publicly accessible datasets (that are generally well anonymized to enable such release) or we are using/creating synthetic datasets that mimic real-world datasets without replicating real people’s data such that they can be identified. In either case, it is essential for Sandbox users to treat person-specific data respectfully and be aware of the additional responsibility and limitations of working with this type of data as part of their career in health data science.
We recommend that users interested in this type of data complete an ethics course on research using health datasets before digging into any analysis. A well regarded course that is also often required for using public databases that contain person-specific data is the Human Subject and Data Research Ethics course designed by the Massachusetts Institute of Technology. The course is hosted at CITI, the Collaborative Institutional Training Initiative. Completing the course is free of charge and provides you with a certificate which you may need to upload to certain databases to gain access. Set up an account at CITI, add an Institutional affiliation with ‘Massachusetts Institute of Technology Affiliates’, and then find and complete the course titled ‘Data or Specimens Only Research’ to obtain a certificate (in pdf form).
Public domain data
The intended scope of the Sandbox is broad, and we will be pulling from many different public access databases (especially for training modules on omics analysis). Databases can be topically broad, giant repositories or field-specific, and each may have its own usage rules. We plan to provide our own copies of publically available datasets where allowed to ensure compatibility with the linked module is preserved, but some datasets may need to be downloaded by users themselves under specific access / distribution restrictions. Many omics datasets do not present significant data sensitivity concerns in comparison to real-world data such as electronic health records (EHRs) and clinical trial datasets.
There are large public de-identified EHR datasets that serve as benchmark resources for teaching and comparing new methods with old, but these are not numerous and often have restricted usage and sharing terms in addition to being quite dated. Historical approaches to dataset anonymization and de-identification have been substantially challenged in the age of digitalized healthcare and increasing data integration, which means meaningfully large ‘anonymized’ datasets are now rarely released.
Synthetic data
Via our collaborators and broader network, the Sandbox has the opportunity to simulate/synthesize data resembling different databases and registries from the Danish health sector. We are exploring methods of creating useful synthetic datasets with national and EU-level data access policies and GDPR restrictions in mind, while developing initial datasets using publicly available data from Danish research studies and other resources.
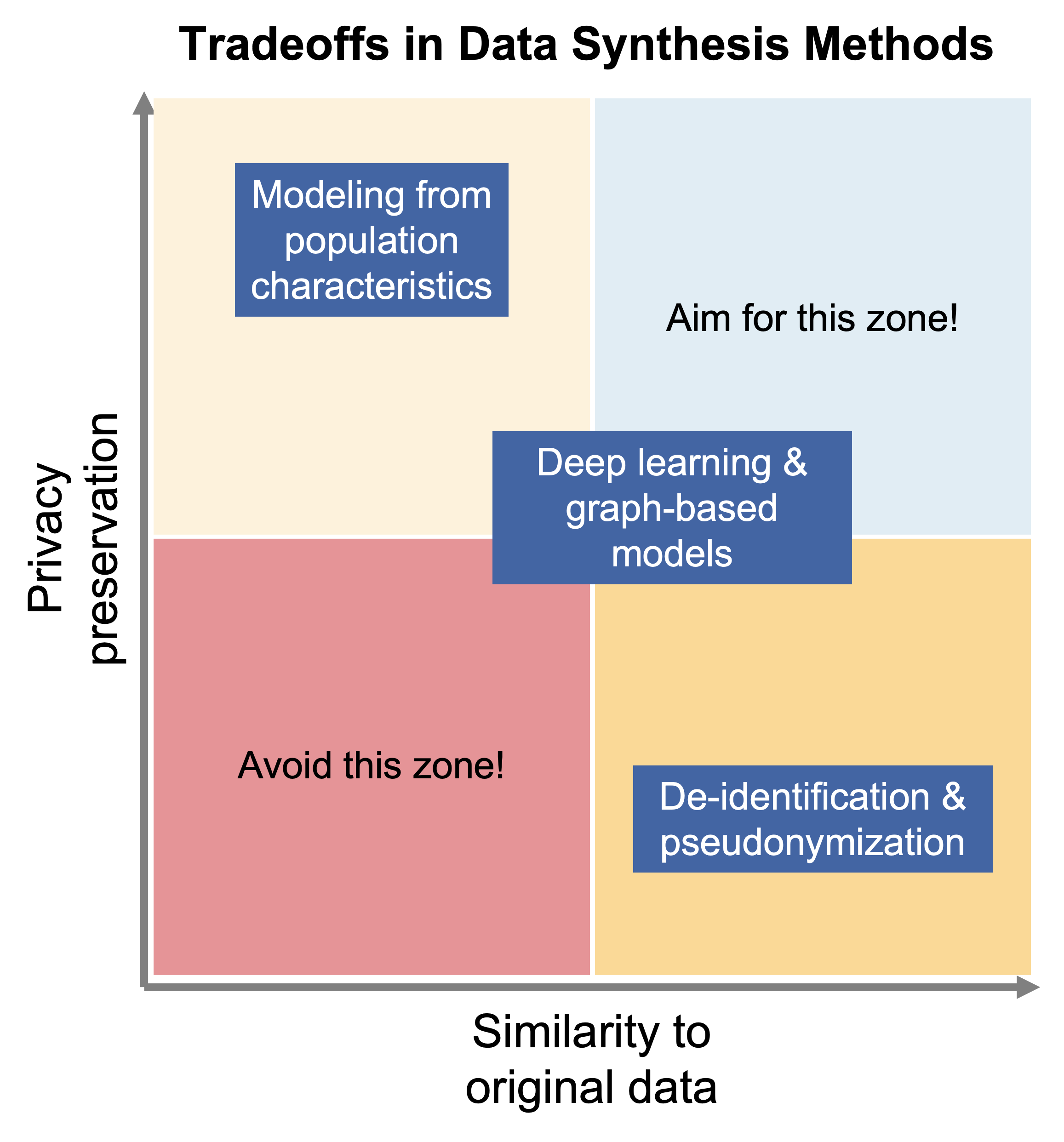
Ultimately, a new era of synthetic data is rapidly developing. The funded Sandbox proposal focused on generating synthetic data using mechanistic models, agent-based models, or draws from multivariate distributions (such as copulas), which are methods that do not present any significant GDPR-related concerns with sharing the produced datasets as they are derived from population-level characteristics and prior knowledge. However, new deep learning-based methods of data synthesis can theoretically learn complex, nonlinear patterns within a sensitive dataset and generate a synthetic dataset that replicates these patterns. This is a really promising approach for sharing high utility synthetic datasets, but it also elevates risk of accidentally sharing too much about the real dataset and skirting the boundaries of GDPR and ethical data handling. There is an inherent trade-off between privacy preservation and similarity of the synthetic dataset to the original dataset, with method development focused on moving closer to the ideal zone of high privacy AND high similarity. The figure at right is a rough approximation of this relationship versus current families of synthesis methods.
Please see Synthetic Data for more information about our approach to this technology.