import warnings
warnings.filterwarnings("ignore")
Tutorial description
This tutorial will cover the basic steps of single cell analysis from preprocessing to the final results production. at the end of this tutorial you will be able to use python to
- Filter your data selecting specific criteria
- Preprocess your data for advanced analysis
- Identify potential cell types
- Perform differential gene expression
- Visualize the basic differentiation dynamics of your data
- Merge datasets and do cross-data analysis
The present tutorial, like the rest of the course material, is available at our open-source github repository and will be kept up-to-date as long as the course will be renewed.
To use this notebook, use the NGS (python) kernel that contains the packages. Choose it by selecting Kernel -> Change Kernel in the menu on top of the window.
A few introductory points to run this notebook (click to show)
- To use this notebook, use the
NGS (Python)kernel that contains the packages. Choose it by selectingKernel -> Change Kernelin the menu on top of the window.
- In this notebook you will use only python commands
- On some computers, you might see the result of the commands once they are done running. This means you will wait some time while the computer is crunching, and only afterwards you will see the result of the command you have executed
- You can run the code in each cell by clicking on the run cell button, or by pressing Shift + Enter . When the code is done running, a small green check sign will appear on the left side
- You need to run the cells in sequential order, please do not run a cell until the one above finished running and do not skip any cells
- Each cell contains a short description of the code and the output you should get. Please try not to focus on understanding the code for each command in too much detail, but rather try to focus on the output
- You can create new code cells by pressing + in the Menu bar above.
Biological background
We will start by analyzing a dataset coming from various sections of human testicular tissue. The testis is a complex organ composed of multiple cell types: germ cells at different stages of maturation and several somatic cell types supporting testicular structure and spermatogenesis (development of cells into spermatozoa); Sertoli cells, peritubular cells, Leydig cells, and other interstitial cells, as outlined in the figure below. Characterizing the various cell types is important to understand which genes and processes are relevant at different levels of maturations of cells into spermatozoa.
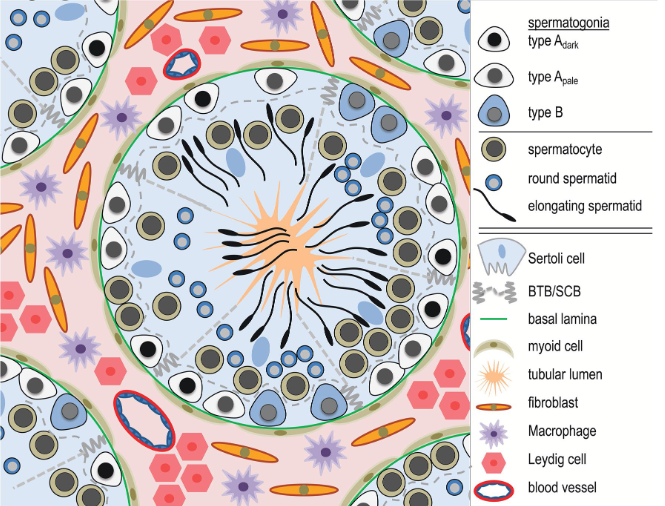
start to develop, beginning from the walls of the tubules towards the center. At the center of the tubule,
spermatozoa will access to the epididymis to reach full maturation.
After characterizing the spermatogenic process, we will perform comparative analysis of our dataset to testicular samples from men affected by azoospermia (reduced or absent froduction of spermatozoa). Infertility is a growing problem, especially in the Western world, where approximately 10–15% of couples are infertile. In about half of the infertile couples, the cause involves a male-factor (Agarwal et al. 2015; Barratt et al. 2017). One of the most severe forms of male infertility is azoospermia (from greek azo, without life) where no spermatozoa can be detected in the ejaculate, which renders biological fatherhood difficult. Azoospermia is found in approximately 10–15% of infertile men (Jarow et al. 1989; Olesen et al. 2017) and the aetiology is thought to be primarily genetic.
Common to the various azoospermic conditions is the lack or distuption of gene expression patterns. It makes therefore sense to detect genes expressed more in the healthy dataset against the azoospermic one. We can also investigate gene enrichment databases to get a clearer picture of what the genes of interest are relevant to.
UMI-based single cell data from microdroplets
The dataset we are using in this tutorial is based on a microdroplet-based method from 10X chromium. From today’s lecture we remember that a microdroplet single cell sequencing protocol works as follow:
- each cell is isolated together with a barcode bead in a gel/oil droplet

</figure>- each transcript in the cell is captured via the bead and assigned a cell barcode and a transcript unique molecular identifier (UMI)
- 3’ reverse transcription of mRNA into cDNA is then performed in preparation to the PCR amplification
- the cDNA is amplified through PCR cycles
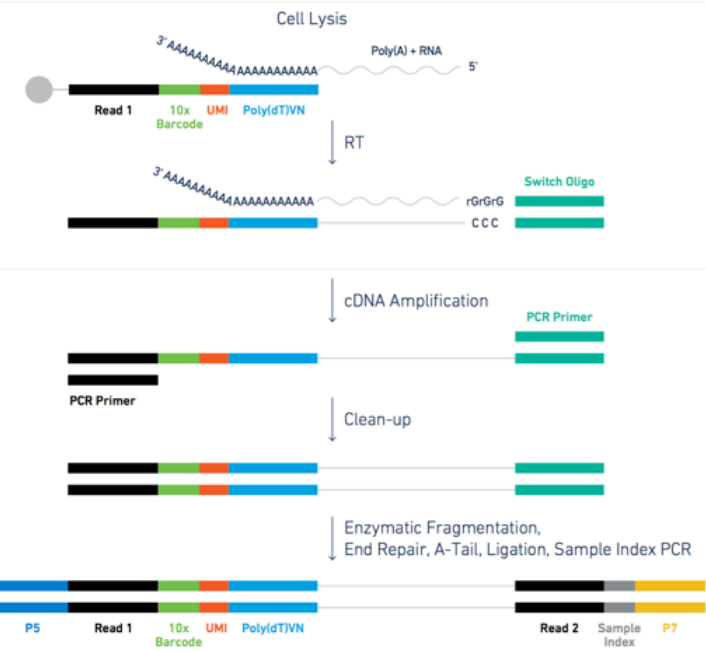
Figure: steps for the microdroplet-based single cell RNA sequencing after isolation.
The raw data in practice
Let’s look at a specific read and its UMI and cell barcode. The data is organized in paired-end reads (written on fastq files), where the first fastq file contains reads in the following format
@SRR8363305.1 1 length=26
NTGAAGTGTTAAGACAAGCGTGAACT
+SRR8363305.1 1 length=26
#AAFFJJJJJJJJJJJJJJJJFJJJJHere, the first 16 characters NTGAAGTGTTAAGACA represent the cell barcode, while the last 10 characters AGCGTGAACT are the transcript UMI tag. The last line represents the quality scores of the 26 characters of barcode+UMI.
The associated second fastq file contains reads of 98nt as the following
@SRR8363305.1 1 length=98
NCTAAAGATCACACTAAGGCAACTCATGGAGGGGTCTTCAAAGACCTTGCAAGAAGTACTAACTATGGAGTATCGGCTAAGTCAANCNTGTATGAGAT
+SRR8363305.1 1 length=98
#A<77AFJJFAAAJJJ7-7-<7FJ-7----<77--7FAAA--<JFFF-7--7<<-F77---FF---7-7A-777777A-<-7---#-#A-7-7--7--The 98nt-long string of characters in the second line is a partial sequence of the cDNA transcript. Specifically, the 10X chromium protocol used for sequencing the data is biased towards the 3’ end, because the sequencing happens from the 3’ to the 5’ end of the transcripts. The last line contains the corresponding quality scores.
Alignment and expression matrix
Once the data is sequenced, it is possible to align the reads to the transcriptome. This is done with tools that are sensible to the presence of spliced transcripts. We will skip the alignment step because it is quite trivial (it requires a pipeline implemented by 10X if you are using 10X data, otherwise you can use one of the available pipelines available on NextFlow), and because it would require too much time and memory for the scope of a one-day tutorial. Instead, we start from the transcript count matrix that results as the output from the transcriptome alignment.
Data analysis
Prepare packages and data necessary to run this python notebook. We will use scanpy as the main analysis tool for the analysis. Scanpy has a comprehensive manual webpage that includes many different tutorials you can use for further practicing. Scanpy is used in the discussion paper and the tutorial paper of this course. An alternative and well-established tool for R users is Seurat. However, scanpy is mainatined and updated by a wider community with many of the latest developed tools.
Note: it can take few minutes to get all the package loaded. Do not mind red-coloured warnings.
import scanpy as sc
import bbknn
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
import os
import gc
import plotly.express as px
import re
import doubletdetectionSome of the commands used in the course are functions we implement to simplify reading the code of this course. Mostly, those are commands requiring lines of code that would not add anything to your learning curve (management of plots, trivial calculations, few management of the notebook layout). However, you are free to look at the code into the file Scripts/pythonScripts.py and to reuse our code in your own work (citing our course).
%run ../Scripts/pythonScripts.pyLoad the dataset.
There are many different possible formats the data can be loaded from. Each format has a dedicated reading command in scanpy, for example read_h5ad, read_10X, read_csv,…. In our case, we have a file already in h5ad format. This format is very convenient to store data with large matrices and their annotations, and is often used to store the scRNAseq expression data after alignment and demultiplexing.
adata = sc.read_h5ad('../Data/scrna_data/rawDataScanpy.h5ad')The data is opened and an Annotated data object is created. This object contains:
- The data matrix
adata.Xof size \(N\_cells \times N\_genes\). The cells are called observations (obs) and the genes variables (var). - Vectors of cells-related variables in the dataframe
adata.obs - Vectors of genes-related variables in the dataframe
adata.var - Matrices of size \(N\_cells \times N\_genes\) in
adata.layers - Matrices where each line is cell-related in
adata.obsm - Matrices where each line is gene-related in
adata.varm - Anything else that must be saved is in
adata.uns

X is the one currently used for analysis.
</figure>The data has 62751 cells and 33694 genes
adata.shape(62751, 33694)If you are running this tutorial on your own laptop and your computer crashes, you might need to subsample your data when you run the code, because there might be some issue with too much memory usage. You can subsample the data to include for example only 5000 cells using the command below (remove the # so that the code can be executed). The results should not differ much from the tutorial with the whole dataset, but you might have to tune some parameters along the code (especially clustering and UMAP projection will look different).
#sc.pp.subsample(adata, n_obs=5000, random_state=12345, copy=False)We calculate quality measures to fill the object adata with some information about cells and genes
sc.preprocessing.calculate_qc_metrics(adata, inplace=True)We can see that now adata contains many observations (obs) and variables (var). Those can be used for filtering and analysis purpose, as well as they might be needed by some scanpy tools
adataAnnData object with n_obs × n_vars = 62751 × 33694
obs: 'batch', 'super_batch', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'n_counts'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts'adata.obs is a dataframe, i.e. a table with indexes on the rows (cell barcodes) and column names (the observation types). One can select a specific observation type by indexing it in the table. We use .head() to show only the first few lines of the dataframe.
adata.obs.head()| batch | super_batch | n_genes_by_counts | log1p_n_genes_by_counts | total_counts | log1p_total_counts | pct_counts_in_top_50_genes | pct_counts_in_top_100_genes | pct_counts_in_top_200_genes | pct_counts_in_top_500_genes | n_counts | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| index | |||||||||||
| AAACCTGAGCCGGTAA-1-0 | Sohni1_und | SohniUnd | 61 | 4.127134 | 511.0 | 6.238325 | 97.847358 | 100.000000 | 100.000000 | 100.000000 | 511.0 |
| AAACCTGAGCGATTCT-1-0 | Sohni1_und | SohniUnd | 2127 | 7.662938 | 5938.0 | 8.689296 | 34.725497 | 45.368811 | 56.113169 | 69.434153 | 5938.0 |
| AAACCTGAGCGTTTAC-1-0 | Sohni1_und | SohniUnd | 3768 | 8.234565 | 8952.0 | 9.099744 | 16.979446 | 24.005809 | 33.031725 | 48.514298 | 8952.0 |
| AAACCTGAGGACAGAA-1-0 | Sohni1_und | SohniUnd | 1588 | 7.370860 | 4329.0 | 8.373322 | 35.458535 | 48.972049 | 60.198660 | 74.867175 | 4329.0 |
| AAACCTGAGTCATGCT-1-0 | Sohni1_und | SohniUnd | 618 | 6.428105 | 962.0 | 6.870053 | 35.654886 | 46.049896 | 56.548857 | 87.733888 | 962.0 |
adata.obs['batch'] #sample label - the data contains 15 separate samplesindex
AAACCTGAGCCGGTAA-1-0 Sohni1_und
AAACCTGAGCGATTCT-1-0 Sohni1_und
AAACCTGAGCGTTTAC-1-0 Sohni1_und
AAACCTGAGGACAGAA-1-0 Sohni1_und
AAACCTGAGTCATGCT-1-0 Sohni1_und
...
TTTGTCACACAGACTT-1-14 Her8_Spc
TTTGTCACAGAGTGTG-1-14 Her8_Spc
TTTGTCAGTTCGGCAC-1-14 Her8_Spc
TTTGTCATCAAACCAC-1-14 Her8_Spc
TTTGTCATCTTCAACT-1-14 Her8_Spc
Name: batch, Length: 62751, dtype: category
Categories (15, object): ['Sohni1_und', 'Sohni2_und', 'Sohni1_I', 'Sohni2_I', ..., 'Her5', 'Her6', 'Her7_Spt', 'Her8_Spc']adata.var works similarly, but now each row is referred to a gene
adata.var.head()| n_cells_by_counts | mean_counts | log1p_mean_counts | pct_dropout_by_counts | total_counts | log1p_total_counts | |
|---|---|---|---|---|---|---|
| index | ||||||
| RP11-34P13.3 | 113 | 0.001865 | 0.001863 | 99.819923 | 117.0 | 4.770685 |
| FAM138A | 0 | 0.000000 | 0.000000 | 100.000000 | 0.0 | 0.000000 |
| OR4F5 | 1 | 0.000016 | 0.000016 | 99.998406 | 1.0 | 0.693147 |
| RP11-34P13.7 | 635 | 0.010805 | 0.010747 | 98.988064 | 678.0 | 6.520621 |
| RP11-34P13.8 | 12 | 0.000191 | 0.000191 | 99.980877 | 12.0 | 2.564949 |
adata.var['n_cells_by_counts'] #nr of cells showing transcripts of a geneindex
RP11-34P13.3 113
FAM138A 0
OR4F5 1
RP11-34P13.7 635
RP11-34P13.8 12
...
AC233755.2 13
AC233755.1 3
AC240274.1 9434
AC213203.1 15
FAM231B 0
Name: n_cells_by_counts, Length: 33694, dtype: int64Preprocessing
We preprocess the dataset by filtering cells and genes according to various quality measures and removing doublets. Note that we are working with all the samples at once. It is more correct to filter one sample at a time, and then merge them together prior to normalization, but we are keeping the samples merged for simplicity, and because the various samples are technically quite homogeneous.
Quality Filtering
Using the prefix MT- in the gene names we calculate the percentage of mithocondrial genes in each cell, and store this value as an observation in adata.obs. Cells with high MT percentage are often broken cells that spilled out mithocondrial content (in this case they will often have low gene and transcript counts), cells captured together with residuals of broken cells (more unlikely if a good job in the sequencing lab has been done) or empty droplets containing only ambient RNA.
MT = ['MT-' in i for i in adata.var_names] #a vector with True and False to find MT genes
perc_mito = np.sum( adata[:,MT].X, 1 ).A1 / np.sum( adata.X, 1 ).A1
adata.obs['perc_mito'] = perc_mito.copy()One can identify cells to be filtered out by looking at the relation between number of transcripts (horizontal axis) and number of genes per cell (vertical axis), coloured by percent of MT genes. We can see that high percentages of mitocondrial genes are present for cells that have less than 1000 detected genes (vertical axis).
sc.pl.scatter(adata, x='total_counts', y='n_genes_by_counts', color='perc_mito',
title='Transcript vs detected genes coloured by mitochondrial content')We can zoom into the plot by selecting cells with less than 3000 genes
sc.pl.scatter(adata[adata.obs['n_genes_by_counts']<3000], x='total_counts', y='n_genes_by_counts', color='perc_mito',
title='Transcript vs detected genes coloured by mitochondrial content\nfor <3000 genes')Another useful visualization is the distribution of each quality feature of the data. We look at the amount of transcripts per cell zooming into the interval (0,20000) transcripts to find a lower threshold. Usually, there is a peak with low quality cells on the left side of the histogram, or a descending tail. The threshold whould select such peak (or tail). In our case we can select 2000 as threshold. Hover on the plots with the mouse to see the value of each bar of the histogram.
fig = px.histogram(adata[adata.obs['total_counts']<20000].obs, x='total_counts', nbins=100,
title='distribution of total transcripts per cell for <20000 transcripts')
fig.show()For the upper threshold of the number of transcripts, we can choose 40000
fig = px.histogram(adata.obs, x='total_counts', nbins=100,
title='distribution of total transcripts per cell')
fig.show()Regarding the number of detected genes, a lower threshold could be around 800 genes. An Upper threshold can be 8000 genes, to remove the tail on the right side of the histogram
fig = px.histogram(adata.obs, x='n_genes_by_counts', nbins=100, title='distribution of detected genes per cell')
fig.show()Cells with too much mitochondrial content might be broken cells spilling out MT content, or ambient noise captured into the droplet. Standard values of the threshold are between 5% and 20%. We select 20%.
fig = px.histogram(adata.obs, x='perc_mito', nbins=100, title='distribution of mitochondrial content per cell')
fig.show()Finally, we look at the percentage of transcripts expressing genes in each cell. We plot the genes showing the highest percentages in a barplot. We can see MALAT1 is expressed in up to 60% of the transcripts in some cells. This can be an indicator of cells with too low quality. Other genes that are highly expressed are of the mitocondrial type and will be filtered out already with the mitochondrial threshold. PRM1, PRM2, PTGDS are typical of spermatogonial processes, and we do not consider those as unusual.
The expression matrix is in compressed format (a so-called sparse matrix), but from now on we will need only the uncompressed matrix. We made a little function to decompress the matrix (array_and_densify).
adata.X = array_and_densify(adata.X)densified%matplotlib inline
fig, ax = plt.subplots(1,1)
ax.set_title('Top genes in terms of percentage of transcripts explained in each cell')
fig = sc.pl.highest_expr_genes(adata, n_top=20, ax=ax)
fig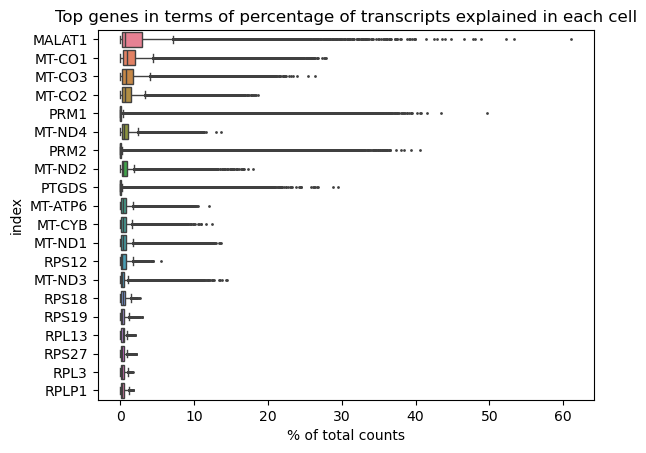
We save the percentages of transcripts expressing MALAT1 and select a threshold for this values. We choose 10% as threshold to cut out the upper tail.
perc_malat = np.sum( adata[:,'MALAT1'].X, 1 ) / np.sum( adata.X, 1 )
adata.obs['perc_MALAT1'] = perc_malat.copy()fig = px.histogram(adata.obs, x='perc_MALAT1', nbins=100, title='Distribution of the amount of MALAT1 transcripts in each cell')
fig.show()Note also how cells with high amount of MALAT1 expression are usually cells of low quality, containing a low amount of transcripts (position the mouse on some of the dots to see the values). This means that many of the cells with high content of MALAT1 will be also filtered out when removing cells with low amount of transcripts. This is compatible with the fact that MALAT1 can indicate dead cells who underwent apoptosis.
px.scatter(data_frame=adata.obs, x='total_counts', y='perc_MALAT1',
title='Relationship between amount of MALAT1 gene and transcripts per cell')We use the following commands to implement some of the thresholds discussed in the plots above
sc.preprocessing.filter_cells(adata, max_genes=8000)sc.preprocessing.filter_cells(adata, min_genes=800)sc.preprocessing.filter_cells(adata, max_counts=40000)adata = adata[adata.obs['perc_mito']<0.2].copy()adata = adata[adata.obs['perc_MALAT1']<0.1].copy()It is good practice to also remove those genes found in too few cells (for example in 10 or less cells). Any cell type clustering 10 or less cells will be undetected in the data, but in any case it would be irrelevant to have such tiny clusters, since statistical analysis on those would be unreliable.
sc.preprocessing.filter_genes(adata, min_cells=10)print('There are now', adata.shape[0], 'cells and', adata.shape[1],'genes after filtering')There are now 49243 cells and 29830 genes after filteringDoublets removal
Another important step consists in filtering out multiplets. We will use the packagescrublet (Wolock et al, 2019), that simulates doublets from the data and compare the simulations to the real data to find any doublet-like cells in it.
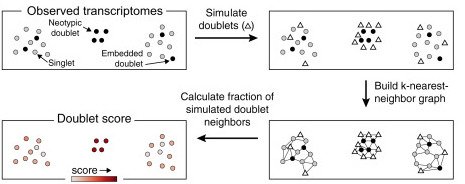
scrublet algorithm, from the related paper.
</figure>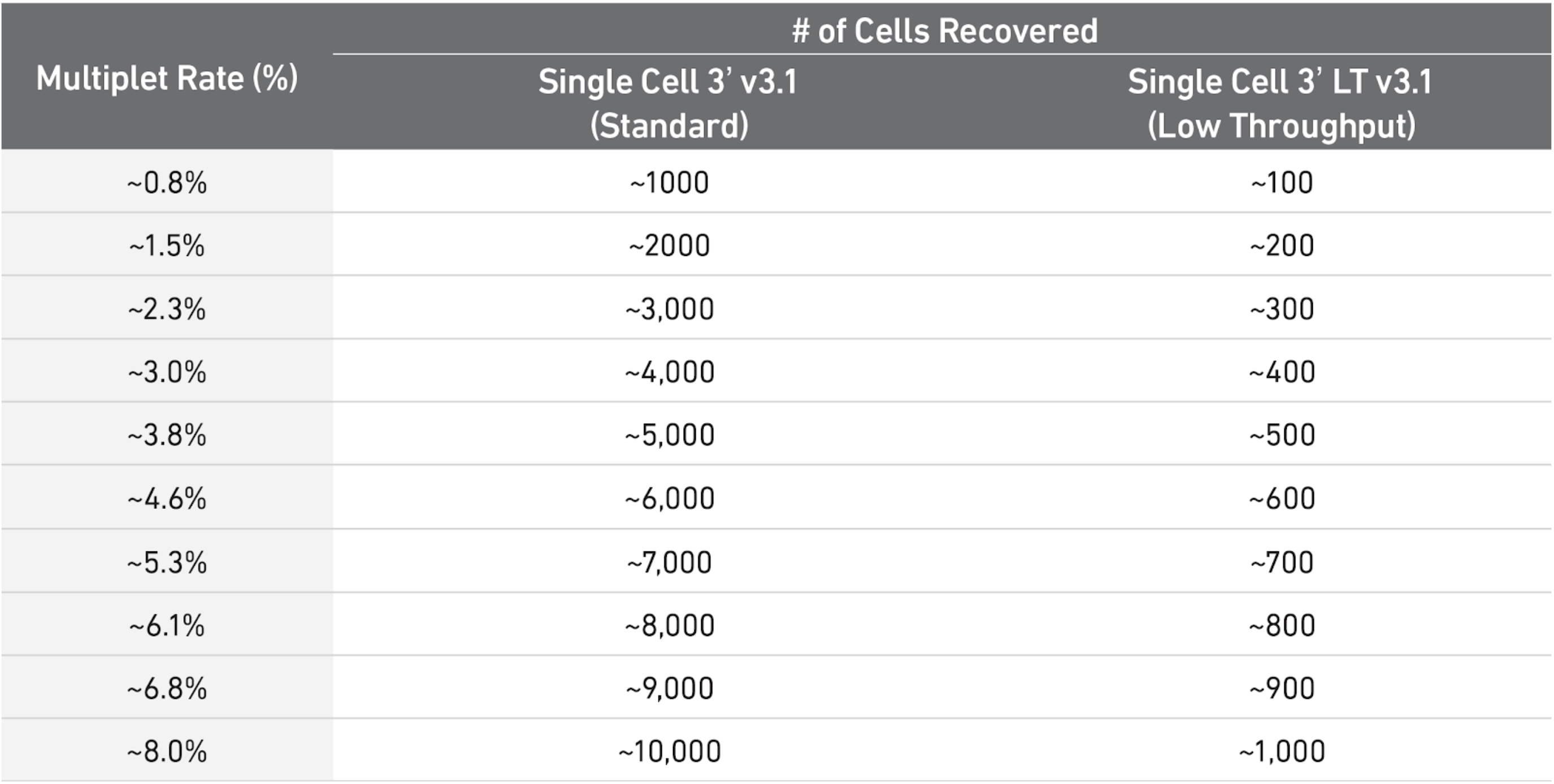
</figure>
Note
Multiplets are in the almost totality of the cases doublets, because triplets and higher multiplets are extremely rare. We will thus talk only about doublets instead of multiplets. Read this more technical blog post for deeper explanations about this fact.
As a rule of thumb, you can have a look at this table to see what is the expected amount of doublets rate for different amounts of cells loaded in a single cell 10X experiment. In our case, each sample ranges somewhere between 3000 and 5000 cells, meaning there were somewhere between 8000 and 10000 loaded cells in each experiment (assuming efficiency of cell capture between 50% and 70%), so one could use 6-8% as a guess.
Below, we run the detection and obtain a score between 0 and 1 for each doublet. We will use that score for filtering
import scrublet
scrub = scrublet.Scrublet(adata.X, expected_doublet_rate=0.08, random_state=123, )
doublet_score, _ = scrub.scrub_doublets(verbose=True)Preprocessing...
Simulating doublets...
Embedding transcriptomes using PCA...
Calculating doublet scores...
Automatically set threshold at doublet score = 0.36
Detected doublet rate = 1.5%
Estimated detectable doublet fraction = 57.3%
Overall doublet rate:
Expected = 8.0%
Estimated = 2.5%
Elapsed time: 120.3 secondsWe gave 8% as expected doublet rate, but note how the algorithm estimated that the doublet rate is estimated to be actually 2-3%. Not far away from what one could guess using the doublet rates’ table, meaning that, in this regard, the data has been produced pretty well.
We now plot the doublet scores assigned to each cell by the algorithm. We can see that most cells have a low score (the score is a value between 0 and 1, where 1 is a theoretically perfect doublet). Datasets with many doublets show a more bimodal distribution (look for example at this jupyter notebook from the scrublet tutorial), while here we just have a light tail beyond 0.1. Therefore we will filter out the cells above this threshold
fig = px.histogram(adata.obs, x=doublet_score, title='Distribution of doublet scores per cell')
fig.show()adata = adata[ doublet_score < .1 ].copy()Data Normalization
Biologically similar cells are not necessarily directly comparable in a dataset because of different technical biases - amongst many the different percentage of captured transcripts (capture efficiency), the presence of technical replicates, the presence of noisy transcripts. The capture efficiency can be influenced by many factors, i.e. the different transcript tags leading to different capture efficiency, the type of protocol used in the laboratory, the amount of PCR performed on different transcripts. Biological biases might as well alter the transcript proportion in a cell, for example in case of different points in the cell cycles altering the expression of specific genes.
To avoid these differences, a normalization approach is needed. Normalization is one of the main topics of scRNAseq data preprocessing, and many advanced techniques take into account the statistical distribution of counts and the presence of technical/biological features of interest (Lytal et al, 2020).
The most standard approach is the TMP (Transcript Per Million) normalization. Here, the transcripts is each cell are rescaled by a factor such that each cell has the same number of transcripts. After TPM rescaling, the data is usually logarithmized, so that a transcript \(x\) becomes \(log(x+1)\). Logarithmization is known to help reducing the technical bias induced by the amount of transcripts in each cell. Finally, the data is standardized with mean 0 and variance 1. This is necessary since the PCA assumes implicitly that datapoints are normally distributed.
As a rule of thumb, TPM works fine but might introduce biases in the data, mostly due to technical differences that are not always removed by normalization. It is possible to use more advanced methods for considering technical and biological covariates as part of a statistical model for the transcripts. One of the current state-of-the-art method is scTransform (Hafemeister and Satija, 2019). This is currently implemented in R.
Effect of normalization on technical features
Before normalizing we look at the highest correlation between the PCA of the raw data and some technical features. The first component of the PCA has the highest \(R^2\) when correlated with the total amount of transcripts. PC5 is mostly correlated with the amount of mitochondrial transcripts. This means that the two PC components mostly describe variations in the technical features and misses the description of biological variation. We will see after normalization that these correlations are reduced. Note that we are plotting the correlations for one specific sample, Guo1, but the concept holds for the remaining samples.
sc.preprocessing.pca(adata, svd_solver='arpack', random_state=12345)
dependentFeatures(adata=adata[adata.obs['batch']=='Guo1'], obs_subset=['total_counts','perc_mito'])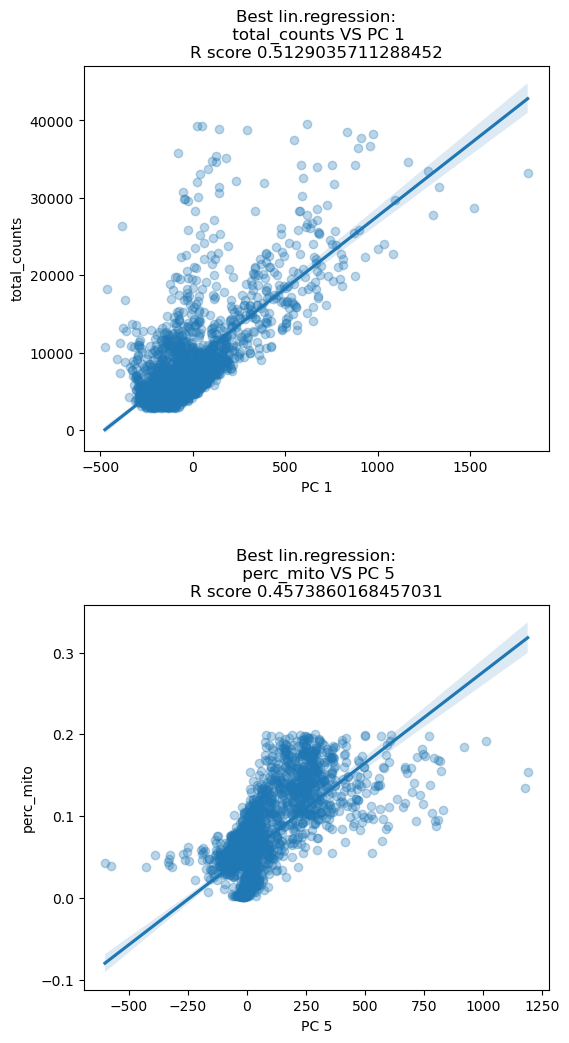
Optional task
Try to look at other samples and see if there are some principal components highly dependent with technical features. You might also want to choose other technical features from the data.
The available samples are
print( list(adata.obs['batch'].cat.categories) )['Sohni1_und', 'Sohni2_und', 'Sohni1_I', 'Sohni2_I', 'Guo1', 'Guo2', 'Guo3', 'Her1_Spg', 'Her2_Spg', 'Her3_Spg', 'Her4', 'Her5', 'Her6', 'Her7_Spt', 'Her8_Spc']and the technical features
print( list( adata.obs.columns ) )['batch', 'super_batch', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'n_counts', 'perc_mito', 'perc_MALAT1', 'n_genes']dependentFeatures(adata=adata[adata.obs['batch'] == ''], #sample name
obs_subset=['total_counts','perc_mito']) #technical features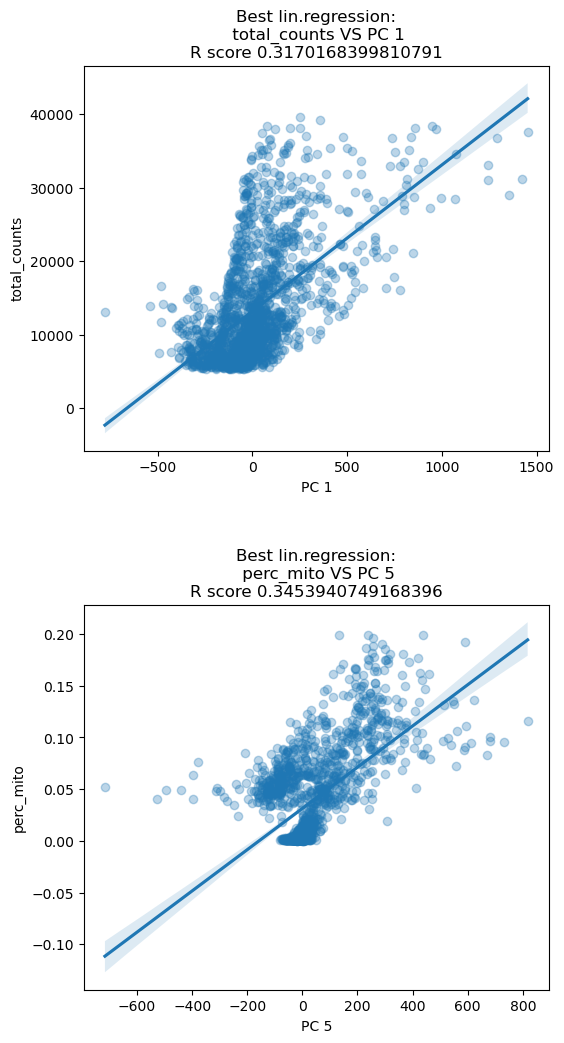
End of optional task
Here we execute the normalization steps. We use the standard TPM normalization and evaluate the result looking at the data projections later on - our datasets are of very good quality, so there will be no problems with the simple TMP normalization. We select also the most variable genes to avoid considering genes that have very constant expression across all the dataset, and are therefore not informative. The most variable genes are used to create the PCA projection of the data, and we can use them also in other parts of the analysis.
When doing normalization, we also want to choose the amount of most variable genes. To do so, we plot the histogram of each gene’s variance, choose a threshold and see how many genes go above that threshold.
variance = np.ravel(np.log1p(np.var(adata.X, axis=0)))
px.histogram(variance, title='Log-variance of each gene')We zoom between 0 and 1, from which we can see decide to set a minimum threshold of 0.05, since we can also see that around 13000 genes have the three smallest variance values in the histograms. 0.05 is the threshold above those bars. There will be around 15000 genes with a variance above 0.05. Keep in mind this value, you will see it is used in the normalization step. Using the most variable genes is useful to avoid noise from genes which do not vary along the data when calculating PCA.
px.histogram(variance, range_x=(0,1), nbins=1000, title='Log-variance of each gene (zoom up to 1)')print(f'{sum(variance>0.05)} genes have a variance above 0.05')14956 genes have a variance above 0.05Finally! Now we can normalize, label the 15000 most variable genes and scale the data
# save raw data matrix
adata.layers['raw_counts'] = adata.X.copy()
# TPM normalization
sc.pp.normalize_per_cell(adata)
# matrix logarithmization
sc.pp.log1p(adata)
# most variable genes
sc.pp.highly_variable_genes(adata, n_top_genes=15000)
#scale
sc.pp.scale(adata)
adata.layers['scaled_counts'] = adata.X.copy()After normalization the linear correlations with technical features are visibly much reduced.
sc.preprocessing.pca(adata, svd_solver='arpack', random_state=123, use_highly_variable=True)
dependentFeatures(adata=adata[adata.obs['batch']=='Guo1'], obs_subset=['total_counts','perc_mito'])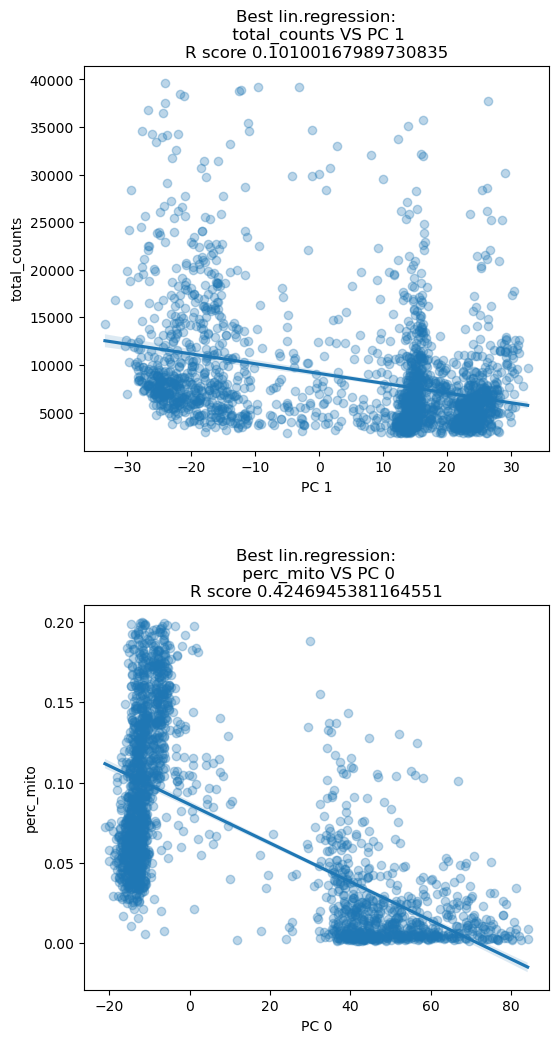
Dimensionality reduction
With the term dimensionality reduction, we intend the projection of each data point (cell) x=[x_1, x_2, , x_{N_{cell}}] into a data point \(y\) in \(D\) dimensions, so that \(y=[y_1, y_2, \dots, y_D]\), where \(D << N_{cell}\).
Dimensionality reduction is meaningful for single cell data analysis, since we know that the genes are expressed in modules of co-expression, meaning that the behaviour of many co-expressed genes can be compressed into the same dimension.
Moreover, using computationally heavy algorithms on the reduced data will help speeding up calculations and reduce memory use, though using a reliable approximation of the full-dimension dataset.
PCA
PCA is one of the most used dimensionality reduction methods. It projects the data by identifying the axis of maximum variation. Since axis are orthogonal, PCA is best for data that has a linear behaviour. However, it has proved to be a reliable method for single cell data, especially to establish the PCA projection as the starting point for computational methods. We calculated the PCA already few lines above, when we checked the correlation with technical variables after normalization.
You can visualize the ratio of variances of each subsequent pair of principal components, where you can see which number of dimensions is best to consider for further applications. Low variance ratios illustrate that along their principal components only little information is represented, probably mostly backgound noise of the dataset. Here we can for example say that 15 dimensions mostly explain the meaningful biological variation in the data. We will use the option n_pcs=15 in some of the functions of scanpy that are based on the PCA.
sc.plotting.pca_variance_ratio(adata)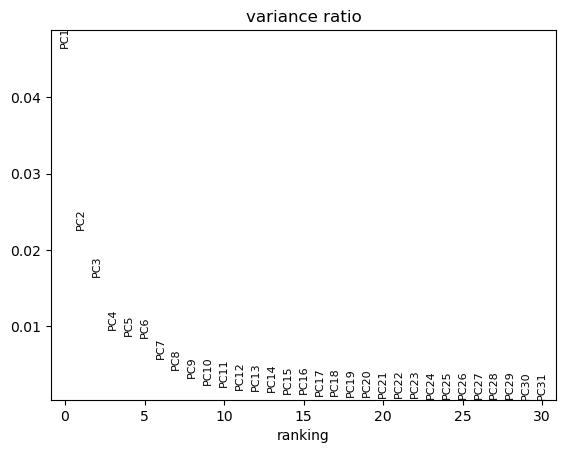
You can plot any dimensionality reduction and colour cells by elements of adata.obs or by gene expression. Below we plot the PCA coloured by different samples composing the dataset, the total number of transcripts and the expression of gene SYCP1. Note how the various samples overlap into the PCA plot. In some cases you can see that the PCA plot is composed of chunks separated by sample, but fortunately this is not our situation.
In such case more advanced techniques for normalization are needed, so that the samples are taken into account. Scanpy has the function sc.pp.combat to normalize accounting samples, but there are many other possibilities such as the package mnnCorrect.
plt.rcParams['figure.figsize'] = (6,6) #reduce figure size
sc.pl.pca(adata, color=['batch','total_counts','SYCP1'])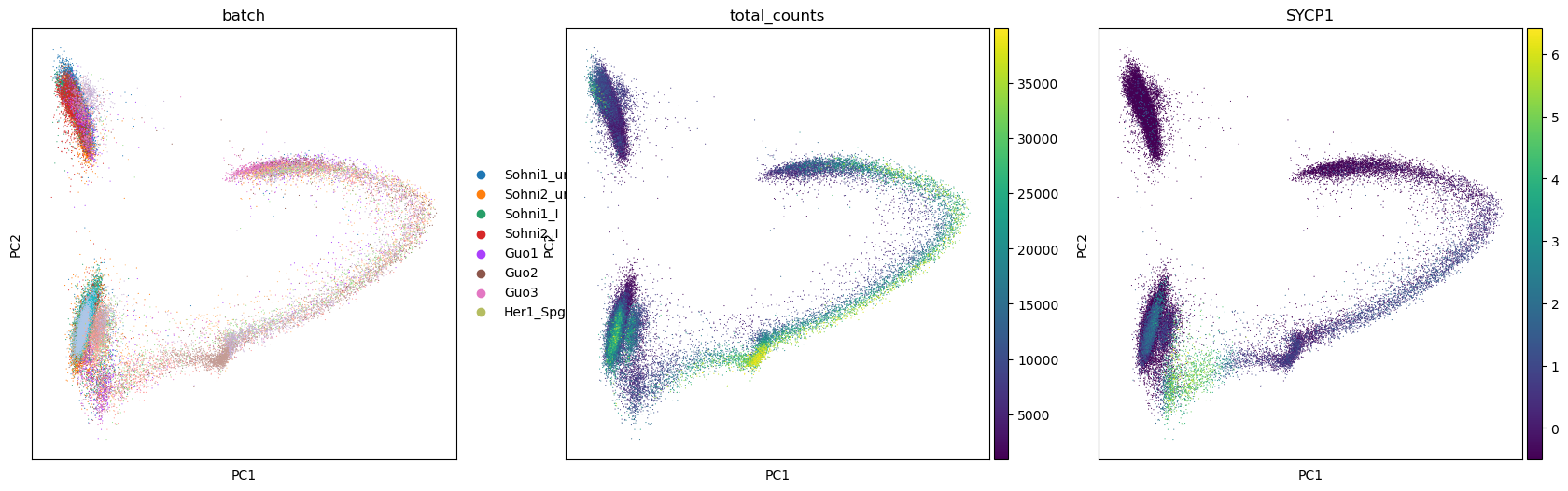
UMAP projection
UMAP (McInnes et al, 2018) is another projection algorithm that finds the optimal formulation of the projection criteria according to some topological theory, aiming at preserving the structure of the high-dimensional graph describing the data. This projection technique has become one of the most used and appreciated, and is structured in a way that calculations are faster than in other algorithms, and scale less than exponentially with the number of dimensions. Explore this “paper with code” to learn about UMAP and its extension applied to neural networks. UMAP has also a manual page with other examples in python.
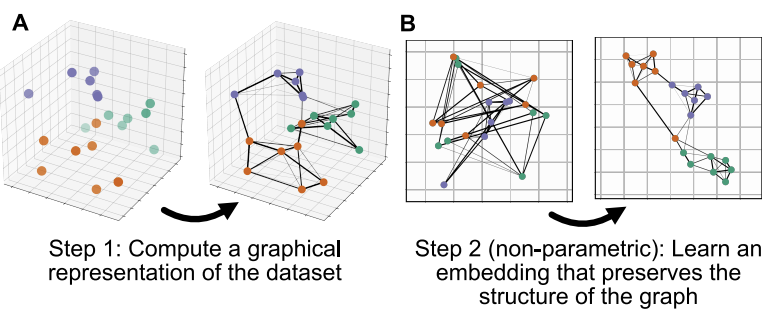
We calculate first the neighborhood of each cell (the distance between the most similar cells). We use the package bbknn to take samples into account and reduce any remaining difference between samples, even though we can see a good overlapping in the PCA plot. In case you haven’t multiple samples, you can use the function sc.pp.neighbors. Note that we impose the use of 15 PCA components.
bbknn.bbknn(adata, n_pcs=15)We calculate and plot the UMAP projection. We calculate three components, so we can also produce a 3d plot. The parameters a and b can be used to strech and compress the projection. Usually they are decided automatically, but you can play with values around 1 to find the plot that is fanciest to you. You are welcome to try various combinations and keep the one you prefere.
sc.tools.umap(adata, random_state=12345, n_components=3, a=.9, b=.9)The plot is made for different pairs of dimensions (1,2 - 1,3 - 2,3) and coloured by a single gene expressed in spermatids. You can observe how there are some smaller clusters separated from a main block of cells looking like a long “snake”. Note also that clusters that seem close to each other, might actually end up being far away when rotating our point of view.
sc.plotting.umap(adata, color=['TNP2'], components=['1,2','1,3','2,3'])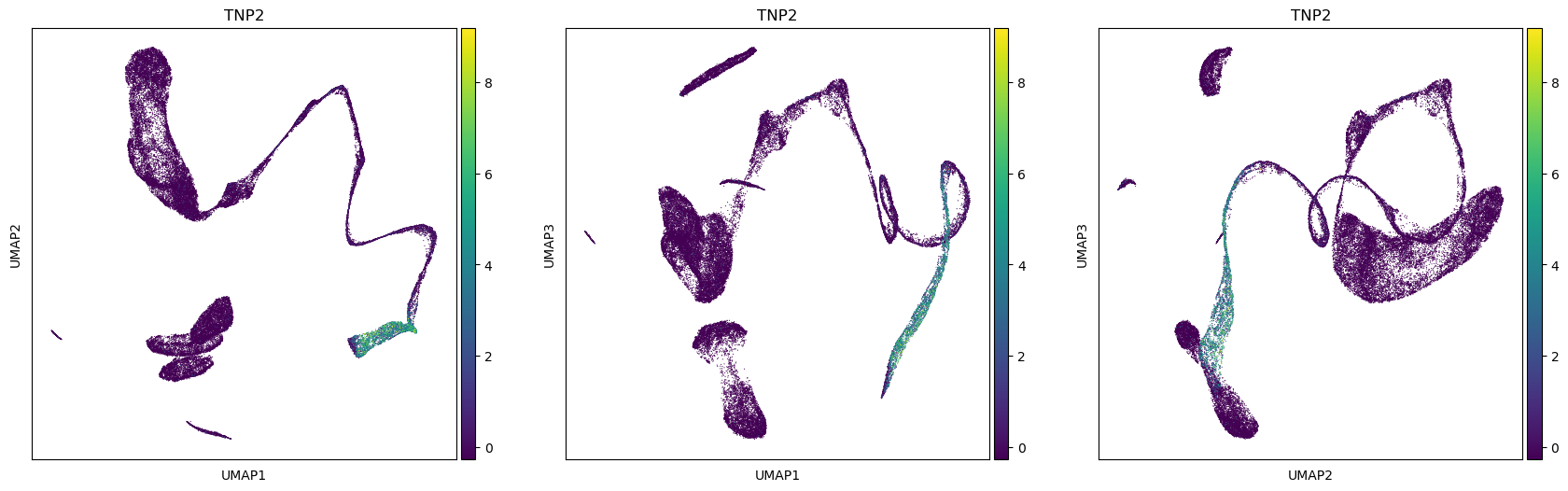
We can look better at the projection in 3D. Here the colour represents the total transcripts per cell. The main group of cells seems twisting at least twice without overlapping, but we do not see any branching. This might mean that there is only one differentiation path. Use the mouse to rotate and zoom in and out the interactive plot.
X = adata.obsm['X_umap']
fig = px.scatter_3d(adata.obsm, x=X[:,0], y=X[:,1], z=X[:,2], color=adata.obs['total_counts'], opacity=.5, height=800)
fig.show()We can also colour by a specific gene. Try any gene you want (inserted here instead of TNP2)
X = adata.obsm['X_umap']
fig = px.scatter_3d(adata.obsm, x=X[:,0], y=X[:,1], z=X[:,2], color=np.ravel(adata[:,'TNP2'].X), height=1000)
fig.show()You can also use a standard plotting command to visualize the 3d plot, but it cannot be rotated interactively
sc.plotting.umap(adata, color=['TNP2'], projection='3d', components=['1,2,3'] )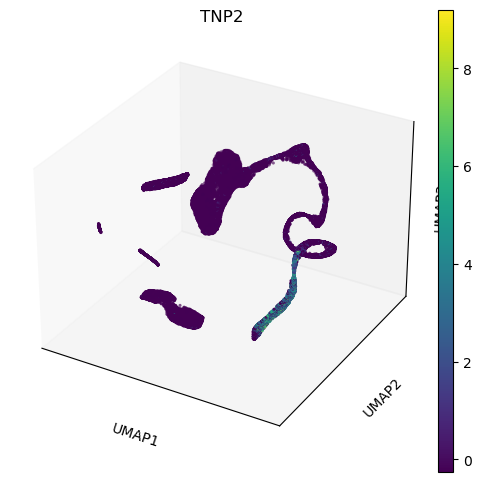
Exercise: tSNE projection
PCA and UMAP are two of the many projection methods available at the moment. Before UMAP, a very popular method was (and still is) tSNE van der Maaten and Hinton, 2008. tSNE tries to match the statistical distribution of the high-dimensional data and its projection. The statistical distribution modeling high-dimensional data is Cryptoled by a parameter called perplexity, defining how far away cells are considered to be in the neighbourhood of a cell. The largest the perplexity, the farther away cells are going to be pulled close to each other in the tSNE projection. In general, tSNE is not very good at keeping the global behaviour of the data into account, while it often pulls cells together in separate chunks.
Changing the perplexity can change a lot the output of tSNE, even though it has shown empirically being stable with values between 5 and 50. Here you can experiment different values of the perplexity and plot tSNE. You will see how - for lower perplexities - tSNE cannot keep the dataset together as in the UMAP projection, dividing it instead into many chunks covering a large 2D space. The tSNE algorithm is actually quite slow, especially with increasing perplexity, so we will subsample the dataset to be only 5000 cells. If you must wait too long to get the code executed, reduce this number even more.
You can also change the method measuring distances between points. The standard distance is euclidean, and you can change this parameter with cityblock, cosine, euclidean, l1, l2, manhattan, braycurtis, canberra, chebyshev, correlation, dice, hamming, jaccard, kulsinski, mahalanobis, minkowski, rogerstanimoto, russellrao, seuclidean, sokalmichener, sokalsneath, sqeuclidean, yule. Some of those distances are well-known for people handy with data science or mathematics, others are more obscure.
YOUR_NAME = 'WRITE YOUR NAME HERE'
PERPLEXITY = 5
DISTANCE_METRIC = 'euclidean'adata_sub = sc.pp.subsample(adata, random_state=54321, n_obs=5000, copy=True)sc.tools.tsne(adata_sub, random_state=54321, perplexity=PERPLEXITY, metric=f'{DISTANCE_METRIC}')sc.plotting.tsne(adata_sub, color=['batch'], legend_loc=None, frameon=False, title=f'{YOUR_NAME}\nPerplexity={PERPLEXITY} Metrix={DISTANCE_METRIC}')
This saves the plot in the folder figures using your name, perplexity parameter and distance metric, so that you can save all your tSNE attempts.
sc.plotting.tsne(adata_sub, color=['batch'], legend_loc=None, frameon=False,
title=f'{YOUR_NAME}\nPerplexity={PERPLEXITY} Metric={DISTANCE_METRIC}', show=False,
save=f'{YOUR_NAME}Perplexity={PERPLEXITY}Metric={DISTANCE_METRIC}.png')WARNING: saving figure to file figures/tsneWRITE YOUR NAME HEREPerplexity=5Metric=euclidean.png<AxesSubplot: title={'center': 'WRITE YOUR NAME HERE\nPerplexity=5 Metric=euclidean'}, xlabel='tSNE1', ylabel='tSNE2'>Clusters Identification
Cell types can be identified and then assigned to clusters calculated by one of the many available clustering techniques. When identifying a cluster, we can assign that to a likely cell type by visualizing known markers on a projection plot, e.g. an UMAP plot. Similarly, one can score cells for a set of markers. Finally, if an atlas of cell types is available, one can use it for a supervised assignment of cell types (see for example the R package scmap) and the ingest tool from scanpy.
Be aware that clusters do not necessarily match perfectly cell types (especially if cells change in a continuous way, hard clusters are not the best solution, though an acceptable one).
Print markers’ scores
The first step to identify various cell types is to print markers on the UMAP plot. We will print markers’ scores, that is the average expression of a list of markers, subtracted of the average expression of some random genes. We provide a python dictionary including some cell types and a few of their marker genes.
A dictionary is a python object in which you can allocate different objects (matrices, vectors, lists, …), each having an assigned name. Here, we have lists of marker genes, where each list is identified by the name of the corresponding cell type. To remember the different stages of spermatogenesis, a scheme is attached below, and you can read more about the spermatogenic process at this page
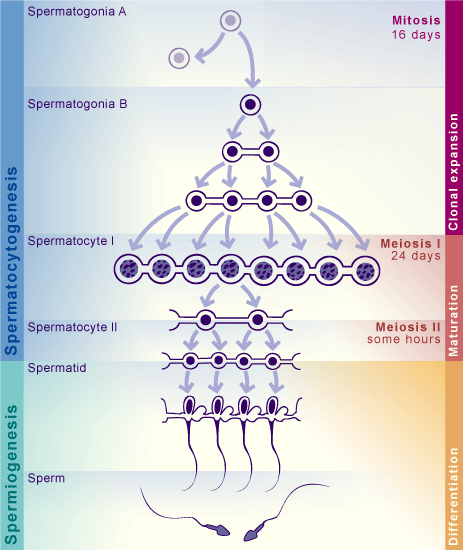
markers = dict() #make an empty dictionary
### SPERMATOCYTOGENESIS
markers['SpermatogoniaA'] = ['ID4','HMGA1']
markers['SpermatogoniaB'] = ['MKI67','DMRT1','STRA8']
markers['SpermatocytesI'] = ['MEIOB','PRSS50','SYCP1','TEX101']
markers['SpermatocytesII'] = ['PIWIL1','ACRV1','SPATA16','CLGN']
### SPERMIOGENESIS
markers['Round.Spt'] = ['SPATA9','SPAM1'] #Round spermatids
markers['Elong.Spt'] = ['PRM1','PRM2'] #Elongated spermatids
### SOMATIC CELLS
markers['Sertoli'] = ['CTSL', 'VIM']
markers['Macroph'] = ['CD163','TYROBP']
markers['Leydig'] = ['CFD']
markers['Endothelial'] = ['CD34']
markers['Myoid'] = ['ACTA2']
markers['Smooth_Muscle'] = ['RGS5']We calculate the scores for the markers
markers_scores, adata = marker_score(markers, adata)Make a separate UMAP plot for every cell type. You should be able to see quite clearly some clusters where the marker’s expressions are stronger. Sertoli cells are usually hard to identify - their markers are expressed also in other cell types, and often Sertoli cells are not captured due to their size. It seems that there aren’t sertoli cells into our dataset.
sc.plotting.umap(adata, color=markers_scores, components=['1,2'], ncols=2, vmax=5, s=30, cmap='Blues')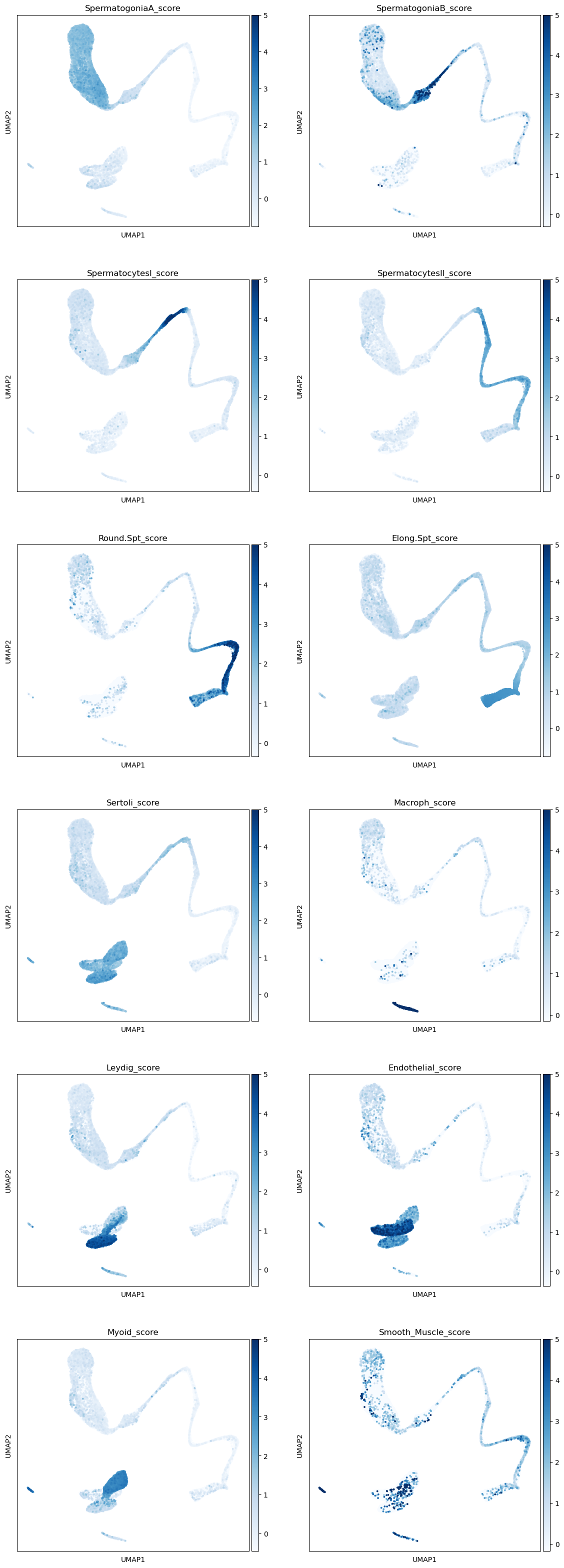
Leiden clustering algorithm
Scanpy contains the leiden algorithm (Traag et al, 2019), making clusters whose points are well connected and at the same time mostly disconnected from other clusters. Other approaches, e.g. k-means, can be performed on the data or on its PCA/tSNE/UMAP projection. The leiden algorithm is however considered to be one of the best techniques at the moment to find communities of similar datapoints, and we will therefore use that. Read more about the leiden algorithm here.
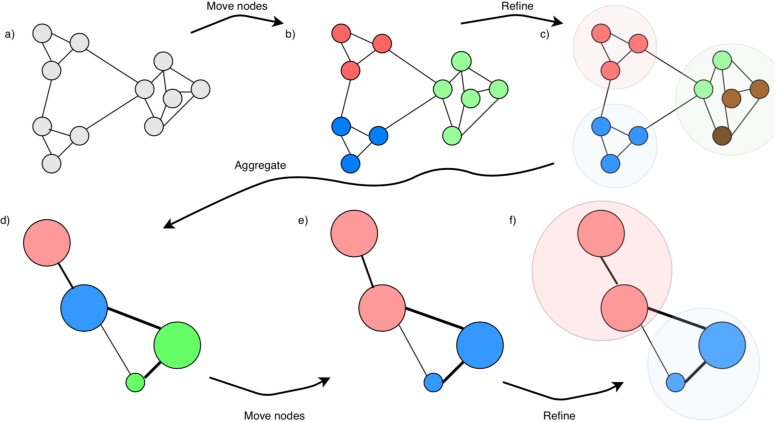
leiden algorithm to find communities of well-connected points.
</figure>We calculate some clusterings at various resolution, and choose the one matching best the clusters we have visualized from the markers’ score. The amount of clusters depend on the chosen resolution. Later in this tutorial, we will integrate this dataset with another one, showing how to cluster the new data using ours as a “reference” clustering.
#leiden clustering at various resolutions
sc.tools.leiden(adata, resolution=1, random_state=12345, key_added='leiden_R1')
sc.tools.leiden(adata, resolution=0.5, random_state=12345, key_added='leiden_R.5')
sc.tools.leiden(adata, resolution=0.25, random_state=12345, key_added='leiden_R.25')
sc.tools.leiden(adata, resolution=0.1, random_state=12345, key_added='leiden_R.1')We can see that at resolution 1 we have many clusters, and their number decreases with decreasing resolution. We choose resolution 0.5 which has enough clusters to have a fine grained cell type assignment.
sc.plotting.umap(adata, color=['leiden_R1','leiden_R.5','leiden_R.25', 'leiden_R.1'], legend_loc='on data', ncols=2)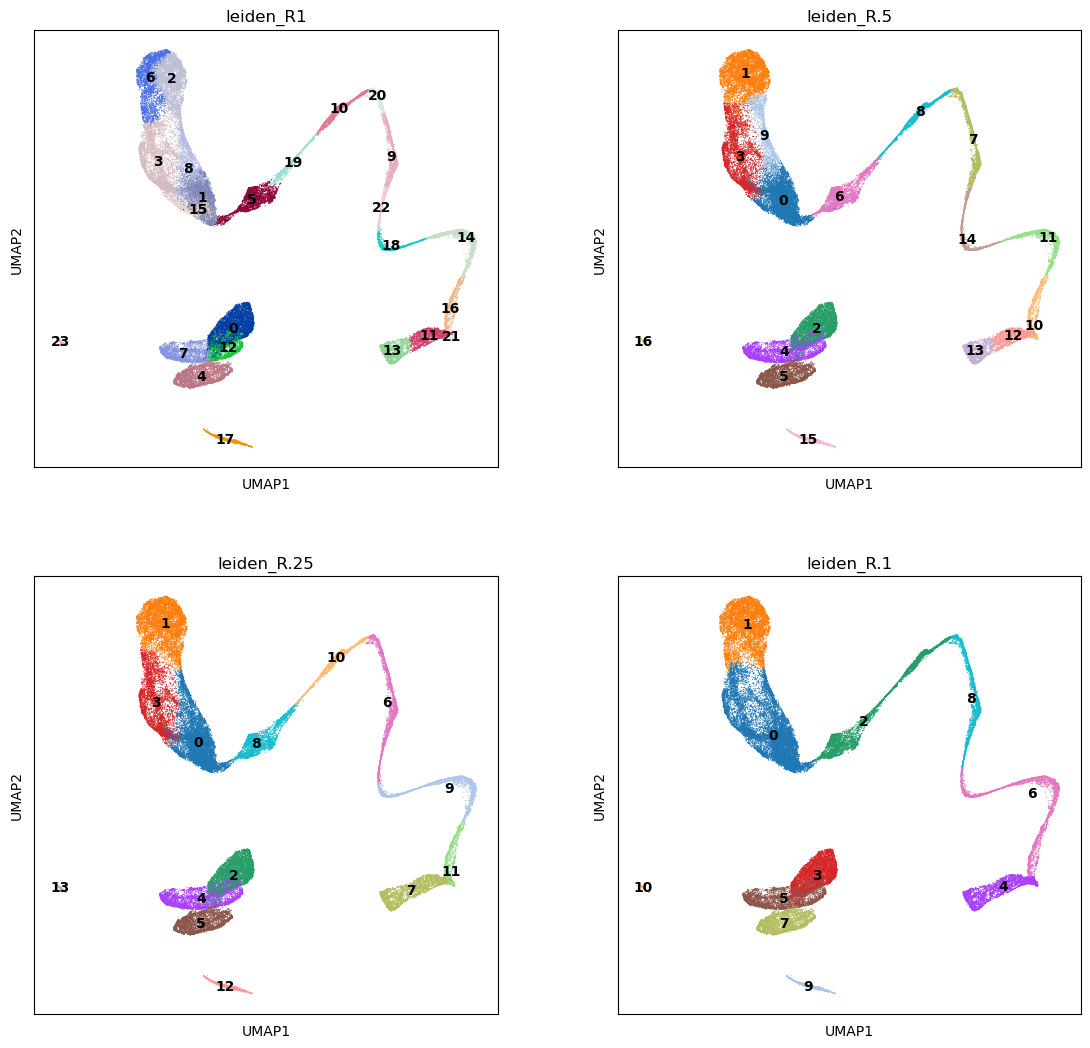
Differential Gene expression
It is not always easy to assign clusters from marker scores. For example, cluster 12 at resolution 0.25 is not immediately recognizable as pericyte cells. Sometimes it is good to double check which genes are most expressed in a cluster compared to all the others before assigning cell types. Here we look at the 50 most expressed genes in each cluster from the Leiden algorithm.
Differential gene expression is also the way of making a sound argument in a publication or report. Showing fancy UMAP plots coloured by gene expression is sadly not enough :) A standard way to do it, is to test if each gene has mean expression higher in a cluster than in all the others. Scanpy does that by using a t-test or the wilcoxon test. While the t-test is somewhat less powerful, the wilcoxon test is not best behaved with very sparse data, so we simply apply the default t-test to the dataset. Note that, for the standard t-test in scanpy, you need to use logarithmized data.
More advanced techniques that model the statistical properties of the data, such as its sparsity, are available for differential expression. See for example the package MAST (Finak et al, 2015) and the following review on differential expression methods: (Squair et al, 2021).
#Perform the test on logarithmized data
adata.X = adata.layers['raw_counts'] #raw data
sc.pp.normalize_total(adata) #TPM normalization
sc.pp.log1p(adata) #logarithm
sc.tl.rank_genes_groups(adata, groupby='leiden_R.5', n_genes=50) #Top 50 diff.expressed genes in each cluster
adata.X = adata.layers['scaled_counts'] #Set again the scaled data as standard data matrixWARNING: adata.X seems to be already log-transformed.Organize result in a table. Each column has the cluster numbers with _N, _P, _L representing respectively the gene Names, their P-values and the Log-fold change of each gene expression compared to the other clusters. Many clusters show markers typical of spermatogenesis processes (MYL9, TEX-genes, …)
result = adata.uns['rank_genes_groups']
groups = result['names'].dtype.names
X = pd.DataFrame(
{group + '_' + key[:1].upper(): result[key][group]
for group in groups for key in ['names', 'pvals_adj','logfoldchanges']})
X.head() #print only first five lines| 0_N | 0_P | 0_L | 1_N | 1_P | 1_L | 2_N | 2_P | 2_L | 3_N | ... | 13_L | 14_N | 14_P | 14_L | 15_N | 15_P | 15_L | 16_N | 16_P | 16_L | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LYPLA1 | 0.0 | 2.635769 | ZNF428 | 0.0 | 3.806565 | PTGDS | 0.0 | 7.961807 | MT-CO2 | ... | 8.849788 | ANKRD7 | 0.0 | 5.520726 | TMSB4X | 0.0 | 5.302206 | MALAT1 | 0.000000e+00 | 3.612107 |
| 1 | SRSF9 | 0.0 | 2.288302 | HMGA1 | 0.0 | 3.570310 | IGFBP7 | 0.0 | 6.235969 | SBNO1 | ... | 6.715557 | CMTM2 | 0.0 | 5.160422 | B2M | 0.0 | 5.034176 | MYL9 | 2.031513e-297 | 6.074902 |
| 2 | SMS | 0.0 | 2.876471 | RPS12 | 0.0 | 2.645890 | ACTA2 | 0.0 | 7.899968 | MT-CO1 | ... | 5.880414 | TEX40 | 0.0 | 5.001250 | TMSB10 | 0.0 | 4.341215 | CALD1 | 9.825148e-295 | 4.660460 |
| 3 | HMGA1 | 0.0 | 2.629156 | RAC3 | 0.0 | 4.114265 | APOE | 0.0 | 6.465453 | MT-CYB | ... | 5.738638 | ROPN1L | 0.0 | 4.393602 | TYROBP | 0.0 | 10.120045 | TMSB4X | 0.000000e+00 | 3.789072 |
| 4 | PFN1 | 0.0 | 2.365119 | GNB2L1 | 0.0 | 2.468919 | CALD1 | 0.0 | 4.854297 | MT-ND4 | ... | 5.993700 | TSACC | 0.0 | 4.597932 | CD74 | 0.0 | 7.758448 | ADIRF | 1.545145e-272 | 6.255490 |
5 rows × 51 columns
The table can also be exported into csv format in the folder results_scrna. It can be opened using jupyterlab as well Excel if you download it and set the comma character , as separator
!mkdir -p results_scrnaX.to_csv('./results_scrna/DiffExpression_NoAnnotation.csv', sep=',', index=None)Cluster assignment
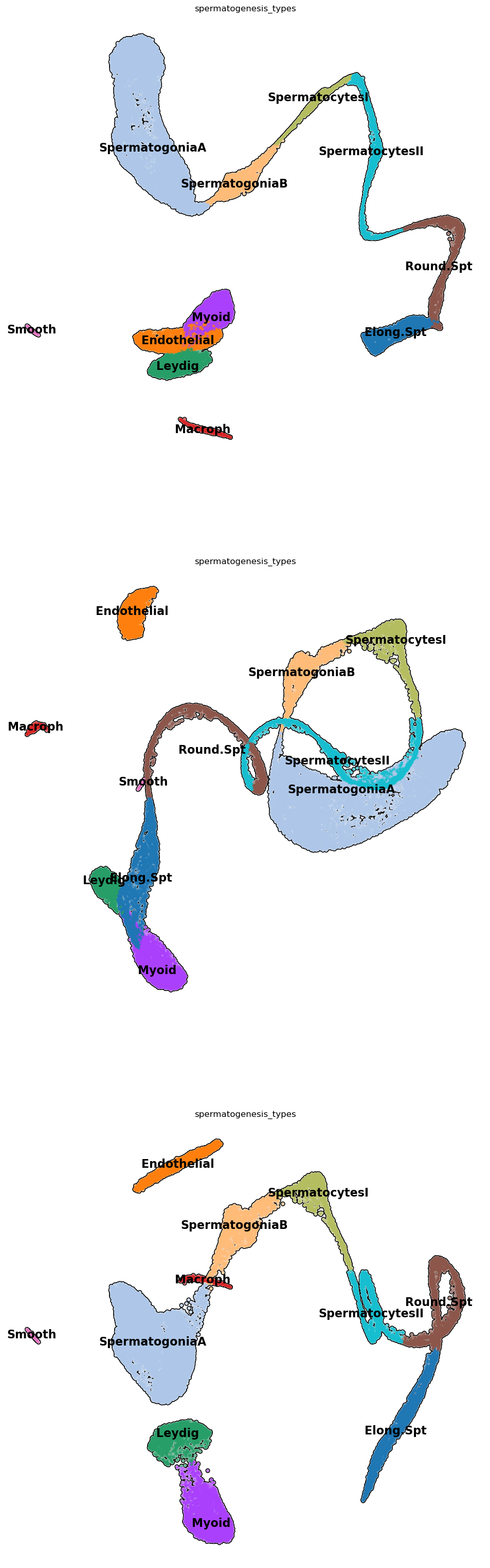
Defining the most likely cell type present in a cluster is sometimes a very complicated task, especially in big datasets where the cells change from one type to another in a very continuous fashion, making the “hard clustering” not a completely realistic model. However, for many applications, a hard clustering associated with a careful markers analysis is a well-accepted technique in the scientific community, and is used in basically the totality of the state-of-the-art publications. To avoid the subjectivity of assigning clusters by hand, we get the best score for each cell type in each of the clusters. To do that, we average the markers scores calculated before with an ad-hoc function we wrote
adata.obs['spermatogenesis_types'] = clustersByScores(adata, markers_scores, leidenClusters=adata.obs['leiden_R.5'])Let’s see how things look like! It seems we have a pretty uniform cluster naming!
plt.rcParams['figure.figsize'] = (12,12)
sc.pl.umap( adata, color=['spermatogenesis_types'],
legend_loc='on data',
legend_fontsize=16,
frameon=False,
size=60,
add_outline=True,
ncols=1,
components=['1,2','2,3','1,3']
)
Exercise: Gene Enrichment Analysis
Gene enrichment analysis consists in testing a set of genes to see if it overlaps significantly with lists of genes contained in a database (Maleki et al, 2020). There are all sorts of databases related to biological pathways, Tissue types, Transcription factors coexpression, Illnesses, … that contain a priori information about sets of genes.
We will try to find enrichment of genes for pathways, ontologies or diseases from the differentially expressed genes of a cluster, and we will create a “consensus ontology” collected from all the people in the course. We will use Enrichr (Chen et al, 2013), that has a web interface of easy use. In this exercise, you will - choose one of the identified clusters - printout a file with a list of differentially expressed genes from the chosen cluster - open the txt file (in the folder results_scrna) and copy the whole list - paste the list in the Enrichr website - find up to 5 terms you consider to be related to spermatogenesis
There are a lot of databases shown in the results from Enrichr, separated in various tabs, so many terms will not be necessarily related to spermatogenesis, or they will be related to basic cellular processes common to many tissues.
Remember the available clusters:
print( list( adata.obs['spermatogenesis_types'].cat.categories ) ) ['Elong.Spt', 'Endothelial', 'Leydig', 'Macroph', 'Myoid', 'Round.Spt', 'Smooth', 'SpermatocytesI', 'SpermatocytesII', 'SpermatogoniaA', 'SpermatogoniaB']Choose the cluster name (write it between the two quotes)
CHOSEN_CLUSTER = 'Myoid'Run differential expression
#Perform the test on logarithmized data
adata.X = adata.layers['raw_counts']
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
sc.tl.rank_genes_groups(adata, groupby='spermatogenesis_types', n_genes=50)
#Use again the scaled data as standard
adata.X = adata.layers['scaled_counts']WARNING: adata.X seems to be already log-transformed.Create the table and print the gene names. Highlight and copy them, so they are ready to be pasted.
result = adata.uns['rank_genes_groups']
groups = result['names'].dtype.names
X = pd.DataFrame(
{group + '_' + key[:1].upper(): result[key][group]
for group in groups for key in ['names', 'pvals_adj','logfoldchanges']})
for i in X[f'{CHOSEN_CLUSTER}_N'].values:
print(i)ACTA2
PTGDS
IGFBP7
APOE
CALD1
MYL9
TMSB4X
TPM2
LGALS1
FHL2
MYL6
SPARCL1
MYH11
TIMP1
TIMP3
SMOC2
ENG
VIM
CD63
B2M
SPARC
DPEP1
ITM2B
DCN
EEF1A1
AEBP1
ACTB
RPL10
NGFRAP1
CPE
OSR2
TCEAL4
FTL
MGP
MALAT1
NR2F2
NEAT1
CST3
NUPR1
RPL13A
RPS4X
TSHZ2
RPS8
RPL7
C11orf96
TPM1
BST2
IFITM3
TAGLN
RPL10ANow paste the genes into the Enrichr website, then find possible interesting enriched terms.
Data dynamics
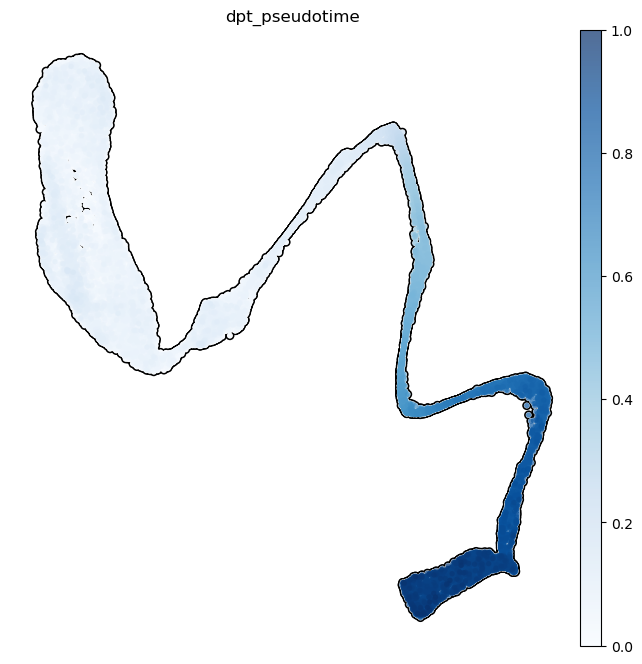
Knowing the beginning of a differentiation process for the cells of an organ, we can model how the development proceeds. This is done by the pseudotimes, based on the statistical concept of diffusion maps (Ronald Coifman and Stephane Lafon, 2006, Angerer et al, 2016): given the cells at the beginning of the differentiation, pseudotimes are a special distance-based measure - imagine being able to walk along the 3D UMAP plot starting from SpermatogoniaA, measuring how much you have walked along the plot. Here we subset the dataset to consider only spermatogenic cells excluding somatic cells.
subdata = adata[ [i not in ['Endothelial','Macroph','Myoid','Smooth','Leydig']
for i in adata.obs['spermatogenesis_types']] ].copy()subdata.uns['iroot'] = np.flatnonzero(subdata.obs['spermatogenesis_types'] == 'SpermatogoniaA')[1]sc.tl.dpt(subdata, n_dcs=2)WARNING: Trying to run `tl.dpt` without prior call of `tl.diffmap`. Falling back to `tl.diffmap` with default parameters.plt.rcParams['figure.figsize'] = (8,8)
sc.pl.umap( subdata, color=['dpt_pseudotime'],
legend_loc='right margin',
legend_fontsize=16,
frameon=False,
size=60,
add_outline=True,
ncols=1,
cmap='Blues'
)
plt.rcParams['figure.figsize'] = (8,8)
X = subdata.obsm['X_umap']
fig = px.scatter_3d(subdata.obsm, x=X[:,0], y=X[:,1], z=X[:,2], color=subdata.obs['dpt_pseudotime'],
hover_name=subdata.obs['spermatogenesis_types'],
height=1000)
fig.show()Note how some clusters have a small variance in pseudotime. This is because those clusters show a lower variability in gene expressions than in cell types where a wide range of differentiation events happen.
sc.pl.violin(subdata, keys='dpt_pseudotime', groupby='spermatogenesis_types', rotation=90,
order=['SpermatogoniaA','SpermatogoniaB','SpermatocytesI','SpermatocytesII','Round.Spt','Elong.Spt'])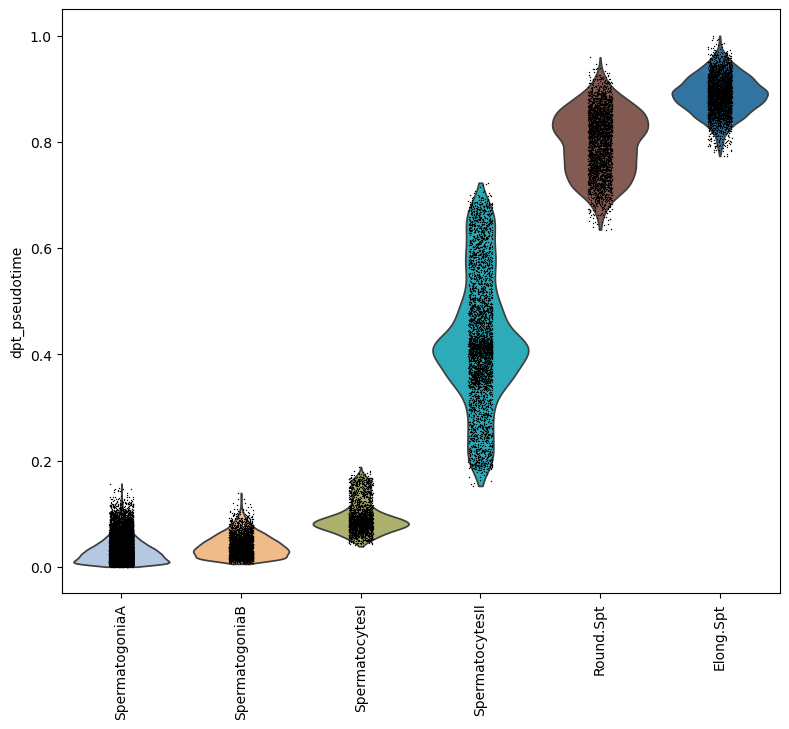
Copy pseudotimes in the main object, leaving somatic cells at a negative value as a default, since they have not a calculated pseudotime
adata.obs['dpt_pseudotime'] = np.repeat(-1, adata.shape[0])
adata.obs['dpt_pseudotime'][subdata.obs_names] = subdata.obs['dpt_pseudotime']remove subdata and use the gc garbage collector to free up memory
#remove subdata as it is no longer used
del subdata
gc.collect() 83077Comparisons across different datasets
In this last part of the analysis we import a dataset of testis tissues from infertile men (affected by cryptozoospermia). The data has already been preprocessed in advance. We will first annotated the new dataset using our spermatogenesis data as a reference, so that cluster names and pseudotimes are assigned accordingly. Then we will compare gene expressions using statistical tests.
Reference-based annotation
We read the new data
crypto = sc.read_h5ad('../Data/scrna_data/crypto_azoospermia.h5ad')#use only genes present in both datasets
var_names = adata.var_names.intersection(crypto.var_names)
adata = adata[:, var_names]
crypto = crypto[:, var_names]The tool ingest included in scanpy allows the annotation of a dataset starting from a reference. Look here for further examples about the use of ingest. We choose the clustering and the pseudotimes as observations to transfer to the new data. It takes some time to do the annotation.
sc.tl.ingest(crypto, adata, obs=['spermatogenesis_types','dpt_pseudotime'])Keep the same cluster colours in the new data
adataView of AnnData object with n_obs × n_vars = 46253 × 12316
obs: 'batch', 'super_batch', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'n_counts', 'perc_mito', 'perc_MALAT1', 'n_genes', 'SpermatogoniaA_score', 'SpermatogoniaB_score', 'SpermatocytesI_score', 'SpermatocytesII_score', 'Round.Spt_score', 'Elong.Spt_score', 'Sertoli_score', 'Macroph_score', 'Leydig_score', 'Endothelial_score', 'Myoid_score', 'Smooth_Muscle_score', 'leiden_R1', 'leiden_R.5', 'leiden_R.25', 'leiden_R.1', 'spermatogenesis_types', 'dpt_pseudotime'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'pca', 'log1p', 'hvg', 'batch_colors', 'neighbors', 'umap', 'leiden_R1', 'leiden_R.5', 'leiden_R.25', 'leiden_R.1', 'leiden_R1_colors', 'leiden_R.5_colors', 'leiden_R.25_colors', 'leiden_R.1_colors', 'rank_genes_groups', 'spermatogenesis_types_colors'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'raw_counts', 'scaled_counts'
obsp: 'distances', 'connectivities'crypto.uns['spermatogenesis_types_colors'] = adata.uns['spermatogenesis_types_colors'] # fix colorsMake pseudotimes as a numeric array
crypto.obs['dpt_pseudotime'] = np.array(crypto.obs['dpt_pseudotime'])Ingest adapts also the UMAP plot of the new data to the reference one. Note how pseudotimes are off for some cell, especially for the Elongated Spermatids cluster. This might be due to reduced spermatogenic functionality of cells in infertile men.
sc.pl.umap(crypto, color=['spermatogenesis_types', 'dpt_pseudotime'], wspace=0.5,
title=['atlas-based clustering of azoospermic data', 'atlas-based pseudotimes of azoospermic data'])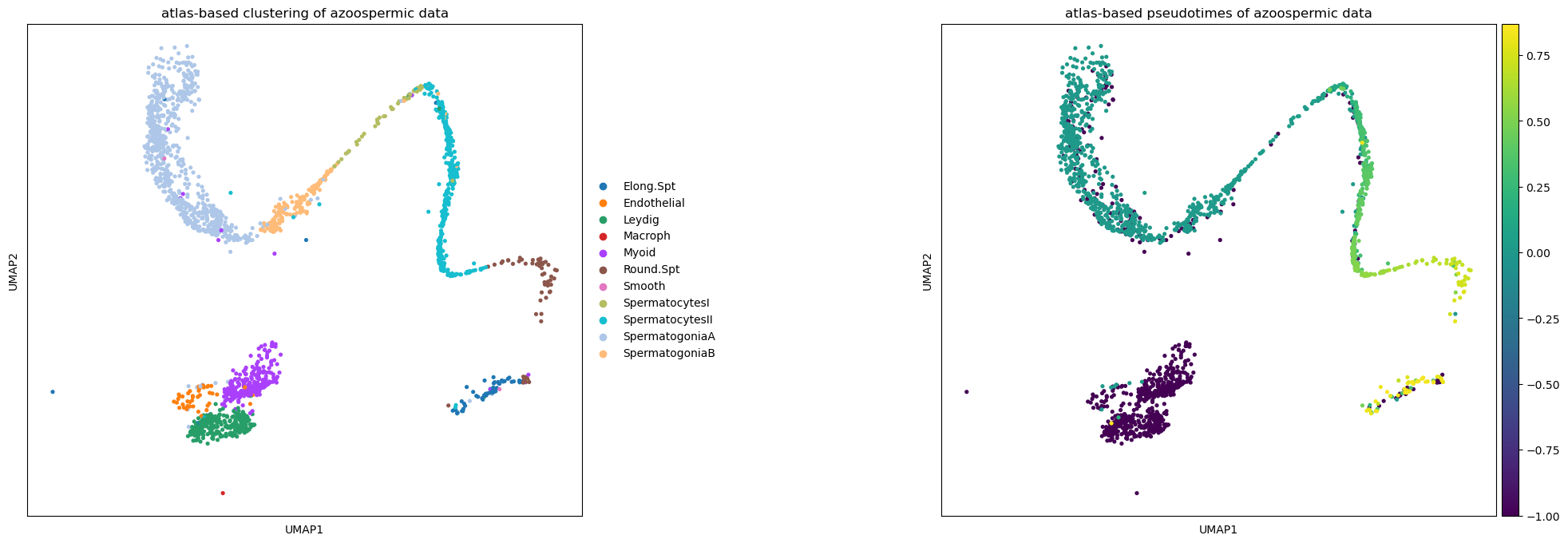
Now we merge the two datasets together. Note that the expression matrix will not be integrated. Ingest is used only for reference-based annotation and UMAP alignment, but it cannot integrate the expression matrices removing biases (such as sample bias). For this there are other tools such as scVI-tools, CCA and rPCA and others. However, a good and computationally lighter alternative is to keep the matrices as they are and model the differences when applying tools on them, as we will do with differential expression testing.
merged = sc.AnnData.concatenate(adata, crypto, batch_key='condition', batch_categories=['Healthy','Crypto'])merged.uns['spermatogenesis_types_colors'] = adata.uns['spermatogenesis_types_colors'] # fix category colorsThe UMAP shows a nice overlapping of the datasets and cluster names, apart from a few cell types that are off
sc.pl.umap(merged, color=['condition','spermatogenesis_types','dpt_pseudotime'], wspace=0.3, s=30)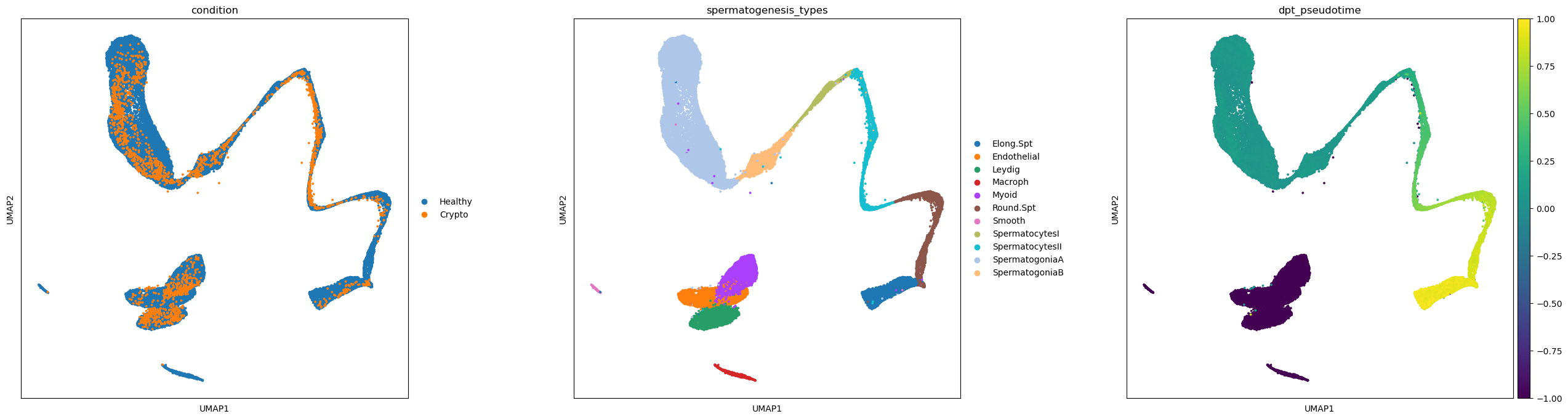
As already noticed before, pseudotimes are quite different between the two conditions
fig, (ax1) = plt.subplots(1, 1, figsize=(12,8), gridspec_kw={'wspace':0.5})
ax = sns.violinplot(x="spermatogenesis_types", y="dpt_pseudotime", hue="condition", scale="width", palette="Set2", split=True, ax=ax1,
data=merged[merged.obs['dpt_pseudotime']>=0].obs[ ['condition', 'dpt_pseudotime', 'spermatogenesis_types'] ],
order=['SpermatogoniaA','SpermatogoniaB','SpermatocytesI', 'SpermatocytesII','Round.Spt','Elong.Spt'])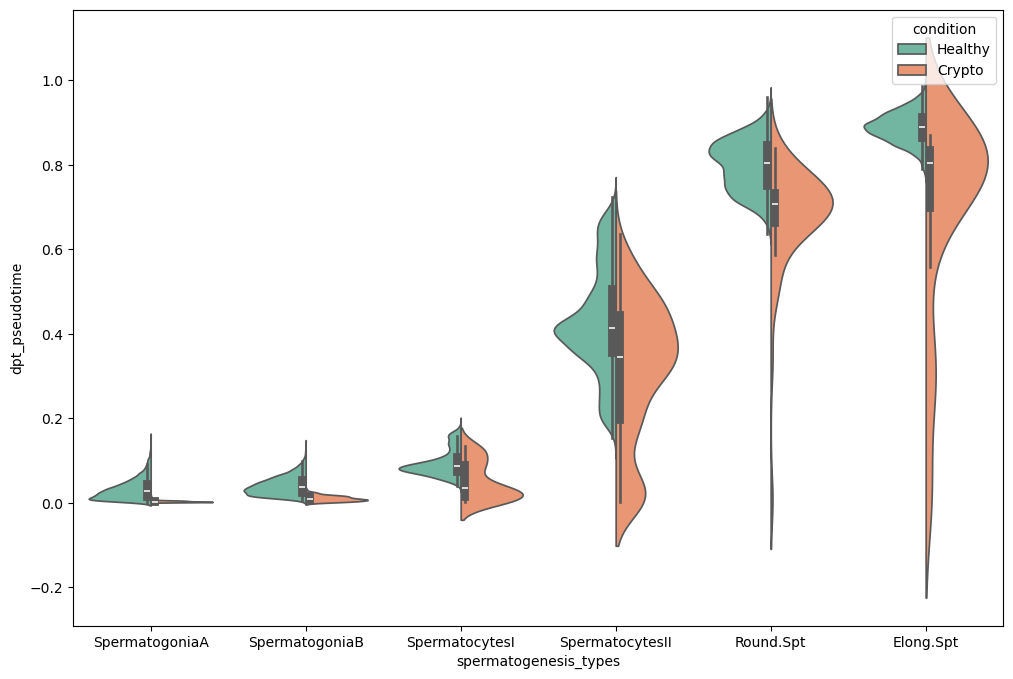
Free some memory up
del adata, crypto
gc.collect() 140277You can save the data like this
merged.write('merged.h5ad')Cross-dataset differential expression
We will perform the differential expression testing between the two conditions. Just to give a very quick overview, you can find three ways in which differential gene expression is done with scRNA-seq data:
- using tests that are analogous to the ones for bulkRNA data. This has been the standard for some years, but generates a lot of false positives, because each cell is used as a bulk sample with very low amount of transcripts.
- using statistical models that take into accounts technical biases in the data (e.g.
D3EandMAST) and should be more reliable than standard bulkRNA methods. Squair et al, 2021 show how those methods are much less effective than previously thought, probably because we still consider each cell as a bulk sample in the test, and the technical differences between cells are just too many to model them. - using groups of cells (in our case grouped by sample, condition and cell type) as a single bulk sample by summing the cells’ transcriptomes. Squair et al, 2021 show how already standard bulkRNA methods applied on the pseudobulk data are very effective and reduce false positives. Right now, this is probably the state-of-the-art way to proceed. Look also at (this other course) for an application of the pseudobulk technique.
We will apply the latter method. To do this we create pseudobulk samples by the sum of the transcriptomes from multiple cells in the data. In other words, we are doing nothing much different than the bulk RNA analysis done in Notebook 3 of this course. We will code only in python, but in future, when working on your own data, you can use any bulkRNA analysis tool with the pseudobulk matrix.
After creating the pseudobulk matrix, we use a standard t-test for differential gene expression. More advanced tools like pydeseq2 have features for including factors in the analysis.
merged = sc.read('merged.h5ad') #read the datamerged.X<Compressed Sparse Row sparse matrix of dtype 'float64'
with 575392627 stored elements and shape (48400, 12316)>We remove mitochondrial and ribosomal genes to focus only on genes of interest.
MT_RP = [('MT-' not in i)and(re.match('^RP[A-Za-z]', i) is None) for i in merged.var_names] #a vector with True and False to find mitocondrial/ribosomal genes
merged = merged[:, MT_RP].copy()We select the raw count matrix for the analysis, and subset the dataset into a new one including the cluster of interest. First, let’s also look at how many cells there are in each cluster of the healthy and azoospermic sample:
merged.X = merged.layers['raw_counts'].copy()merged[merged.obs['condition']=='Healthy'].obs['spermatogenesis_types'].value_counts() #healthy sampleSpermatogoniaA 17512
Myoid 4921
SpermatocytesII 3972
Endothelial 3752
Leydig 3312
Round.Spt 3268
Elong.Spt 3150
SpermatogoniaB 2835
SpermatocytesI 2176
Macroph 946
Smooth 409
Name: spermatogenesis_types, dtype: int64We can see there are many cells in each cell type, but we must also check that each condition has enough. Note that the azoospermia sample is quite little and have few cells in some clusters:
merged[merged.obs['condition']=='Crypto'].obs['spermatogenesis_types'].value_counts()SpermatogoniaA 791
SpermatocytesII 396
Leydig 317
Myoid 275
SpermatogoniaB 162
Round.Spt 58
Elong.Spt 55
SpermatocytesI 47
Endothelial 43
Smooth 2
Macroph 1
Name: spermatogenesis_types, dtype: int64We renormalize the data and take some significant genes. Less variable genes will not be useful for differential expression analysis.
sc.pp.log1p(merged)
sc.pp.normalize_per_cell(merged)
sc.pp.highly_variable_genes(merged, n_top_genes=5000)Now we subset by most significant genes. Afterwards, we use a script to generate the bulk matrix for both conditions. This script always uses the raw counts matrix even if we normalized the data above to find the most variable genes.
matrix = merged[:,merged.var['highly_variable']].X.copy()matrix_bulk, clusters, conditions = pseudobulk_matrix(adata=merged,
batch_key='batch',
condition_key='condition',
cluster_key='spermatogenesis_types')Guo1
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Guo2
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Guo3
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
Only 1 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her1_Spg
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her2_Spg
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
--------Round.Spt
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 1 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her3_Spg
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her4
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her5
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
Only 0 cells: skipping
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
Only 1 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her6
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
Only 1 cells: skipping
--------Myoid
--------Round.Spt
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her7_Spt
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Her8_Spc
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
--------Round.Spt
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
SAM_1
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
----Crypto
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
Only 0 cells: skipping
--------Myoid
--------Round.Spt
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
SAM_2
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
--------Leydig
--------Macroph
Only 0 cells: skipping
--------Myoid
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 1 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
Only 1 cells: skipping
--------SpermatogoniaA
--------SpermatogoniaB
SAM_3
----Healthy
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
----Crypto
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
Only 1 cells: skipping
--------Myoid
--------Round.Spt
--------Smooth
Only 1 cells: skipping
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
Sohni1_I
----Healthy
--------Elong.Spt
Only 1 cells: skipping
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
Only 0 cells: skipping
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Sohni1_und
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Sohni2_I
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
Only 0 cells: skipping
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skipping
Sohni2_und
----Healthy
--------Elong.Spt
--------Endothelial
--------Leydig
--------Macroph
--------Myoid
--------Round.Spt
--------Smooth
--------SpermatocytesI
--------SpermatocytesII
--------SpermatogoniaA
--------SpermatogoniaB
----Crypto
--------Elong.Spt
Only 0 cells: skipping
--------Endothelial
Only 0 cells: skipping
--------Leydig
Only 0 cells: skipping
--------Macroph
Only 0 cells: skipping
--------Myoid
Only 0 cells: skipping
--------Round.Spt
Only 0 cells: skipping
--------Smooth
Only 0 cells: skipping
--------SpermatocytesI
Only 0 cells: skipping
--------SpermatocytesII
Only 0 cells: skipping
--------SpermatogoniaA
Only 0 cells: skipping
--------SpermatogoniaB
Only 0 cells: skippingThe bulk matrix looks like this. It shows the total expression of each gene in every cluster, sample and condition. Those are represented in the bulk sample name, together with a number. Our script actually creates 10 pseudobulk samples per each group of cells, by randomly subsampling them. In this way we still keep some of the single cell variability. This is why each pseudobulk sample has a number. For example: Healthy_Guo1_Elong_Spermatids_2 is the pseudobulk sample number 2 from cells in the healthy condition, sample name Guo1 and cluster Elongated spermatids.
matrix_bulk.head()| Healthy_Guo1_Elong.Spt_0 | Healthy_Guo1_Elong.Spt_1 | Healthy_Guo1_Elong.Spt_2 | Healthy_Guo1_Elong.Spt_3 | Healthy_Guo1_Elong.Spt_4 | Healthy_Guo1_Elong.Spt_5 | Healthy_Guo1_Elong.Spt_6 | Healthy_Guo1_Elong.Spt_7 | Healthy_Guo1_Elong.Spt_8 | Healthy_Guo1_Elong.Spt_9 | ... | Healthy_Sohni2_und_SpermatogoniaB_0 | Healthy_Sohni2_und_SpermatogoniaB_1 | Healthy_Sohni2_und_SpermatogoniaB_2 | Healthy_Sohni2_und_SpermatogoniaB_3 | Healthy_Sohni2_und_SpermatogoniaB_4 | Healthy_Sohni2_und_SpermatogoniaB_5 | Healthy_Sohni2_und_SpermatogoniaB_6 | Healthy_Sohni2_und_SpermatogoniaB_7 | Healthy_Sohni2_und_SpermatogoniaB_8 | Healthy_Sohni2_und_SpermatogoniaB_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FAM41C | 0.0 | 0.0 | 0.000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.000000 | 0.000000 | 0.000000 | 1.305737 | 1.159709 | 0.000000 | 0.000000 | 0.000000 | 0.486395 | 0.000000 |
| SAMD11 | 0.0 | 0.0 | 0.822 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.989435 | 0.602223 | 0.588762 | 0.966829 | 1.158253 | 0.623572 | 1.040643 | 0.304657 | 0.924624 | 1.218390 |
| NOC2L | 0.0 | 0.0 | 0.000 | 0.0 | 0.000000 | 0.743657 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 5.744185 | 2.700832 | 5.782676 | 3.852823 | 3.552665 | 5.052505 | 6.785296 | 3.531232 | 6.631590 | 3.002781 |
| KLHL17 | 0.0 | 0.0 | 0.000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.0 | ... | 0.489320 | 0.000000 | 1.139032 | 0.000000 | 0.782108 | 0.000000 | 0.000000 | 0.000000 | 0.437053 | 0.000000 |
| ISG15 | 0.0 | 0.0 | 0.000 | 0.0 | 0.861346 | 0.000000 | 0.0 | 0.481781 | 0.0 | 0.0 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.163019 | 0.000000 | 0.000000 |
5 rows × 1520 columns
For practical purpose we exchange rows and columns by rotating the matrix.
matrix_bulk = matrix_bulk.T
matrix_bulk.head()| FAM41C | SAMD11 | NOC2L | KLHL17 | ISG15 | C1orf159 | SDF4 | UBE2J2 | SCNN1D | ACAP3 | ... | MCM3AP | YBEY | C21orf58 | PCNT | DIP2A | PRMT2 | AC136616.1 | AC007325.4 | AC023491.2 | AC240274.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Healthy_Guo1_Elong.Spt_0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000000 | 0.524757 | 0.000000 | 7.200664 | 0.0 | 0.0 | ... | 0.000000 | 2.478227 | 0.000000 | 0.493104 | 0.728248 | 0.0 | 1.682502 | 8.850147 | 0.0 | 0.0 |
| Healthy_Guo1_Elong.Spt_1 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000000 | 2.869721 | 0.000000 | 6.047873 | 0.0 | 0.0 | ... | 0.000000 | 3.559190 | 3.714458 | 0.000000 | 0.000000 | 0.0 | 0.864075 | 8.230722 | 0.0 | 0.0 |
| Healthy_Guo1_Elong.Spt_2 | 0.0 | 0.822 | 0.0 | 0.0 | 0.000000 | 1.604822 | 0.000000 | 6.691433 | 0.0 | 0.0 | ... | 0.000000 | 2.366015 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 5.639266 | 0.0 | 0.0 |
| Healthy_Guo1_Elong.Spt_3 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000000 | 0.509491 | 0.680446 | 5.043328 | 0.0 | 0.0 | ... | 0.680446 | 3.762988 | 0.000000 | 1.710508 | 0.680446 | 0.0 | 1.416343 | 7.605245 | 0.0 | 0.0 |
| Healthy_Guo1_Elong.Spt_4 | 0.0 | 0.000 | 0.0 | 0.0 | 0.861346 | 0.420644 | 0.000000 | 6.480343 | 0.0 | 0.0 | ... | 0.000000 | 1.620871 | 0.000000 | 0.000000 | 0.420644 | 0.0 | 0.920444 | 4.049621 | 0.0 | 0.0 |
5 rows × 12173 columns
We create a scanpy object to be able to do statistical testing.
import anndata as adpbulk = ad.AnnData(matrix_bulk)pbulkAnnData object with n_obs × n_vars = 1520 × 12173We just remove those genes never expressed in the pseudobulk data
sc.pp.filter_genes(pbulk, min_cells=1)We create some metadata
pbulk.obs['condition'] = conditions
pbulk.obs['spermatogenesis_types'] = clusters and normalize depth of each pseudobulk replicate and logarithmize, similarly to what was done in Notebook 3 of the course
sc.pp.normalize_per_cell(pbulk)
sc.pp.log1p(pbulk)Out of curiosity, why not plotting a PCA of the pseudobulk data? We can see how it looks similar to the single cell data, with a decent overlapping of the conditions, meaning the pseudobulk process kept the differences between types, and also the data structure overall.
sc.pp.pca(pbulk)sc.pl.pca(pbulk, color=['condition','spermatogenesis_types'], s=50)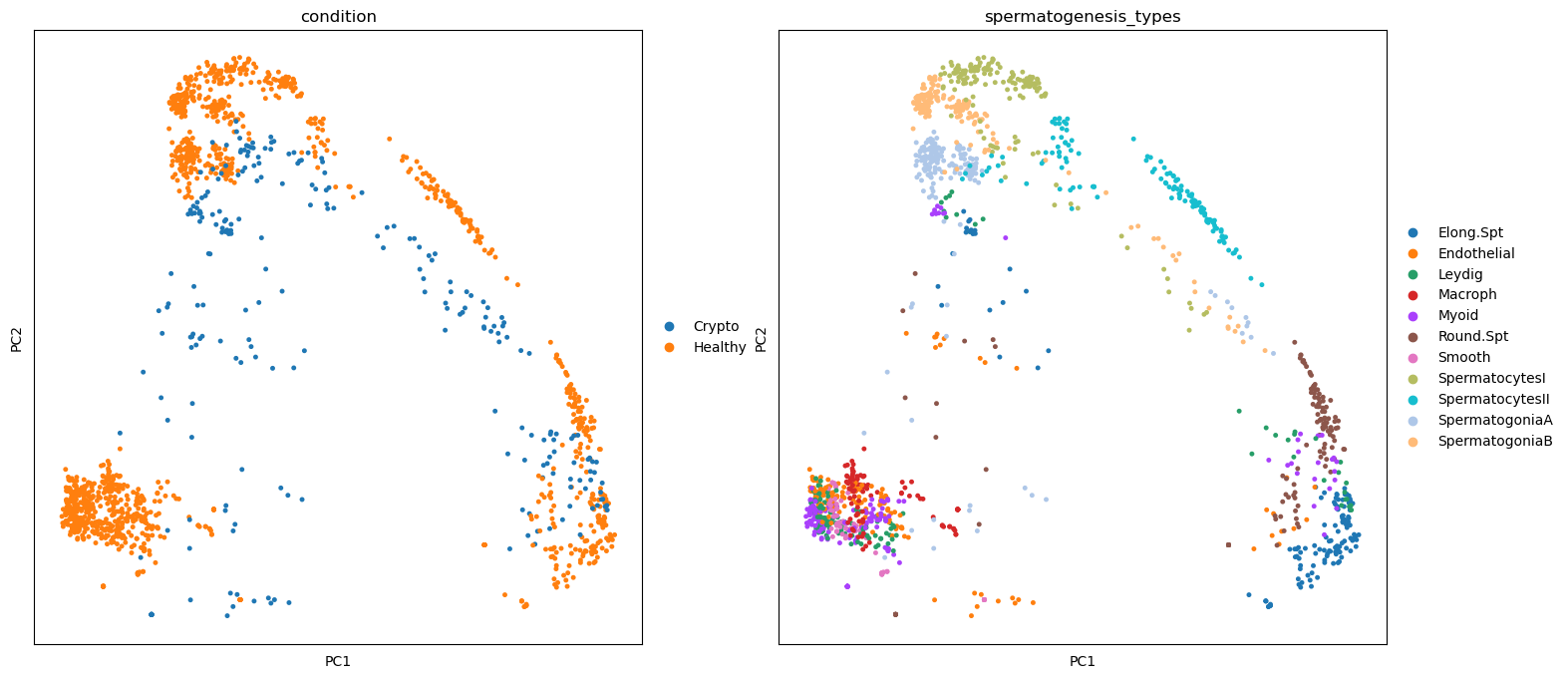
We can finally run the statistical test by condition. We will do a list with ALL genes, so we can explore it at any time afterwards. We will use the condition Healthy as reference, so the results will give how changes are in Crypto against Healthy
sc.tl.rank_genes_groups(pbulk, groupby="condition", reference='Healthy', n_genes=pbulk.shape[1])We use a script to extract the results in a matrix. We will also calculate some other values under the hood and add them in the table.
DEG_matrix = pseudobulk_extract_DEG(pbulk=pbulk, adata=merged)---Extracting results
WARNING: adata.X seems to be already log-transformed.
---doneWhat does the resulting matrix contain? Apart from genes names, we can see in how many bulk samples those are expressed (in percentage for healthy and crypto cells), the fold-change and log-fold-change, the pvalues and adjusted pvalues. Note: those results are for Crypto vs Healthy. For values with Healthy as a reference, just change the sign to all fold-changes and log-fold-changes, and you have changed your reference!
DEG_matrix.head()| Crypto_NAMES | Crypto_PVALS | Crypto_PVALS_ADJ | Crypto_LOGFOLDCHANGES | Healthy_PCT | Crypto_PCT | Crypto_FOLDCHANGES | Crypto_LOGPVALS_ADJ | Crypto_LOGPVALS | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | EEF1G | 4.557527e-188 | 1.849293e-184 | 7.720026 | 3.664627 | 97.345133 | 210.843109 | 50.0 | 50.0 |
| 1 | MRPS24 | 4.462642e-173 | 1.358094e-169 | 6.370932 | 2.181480 | 80.763857 | 82.764008 | 50.0 | 50.0 |
| 2 | GABARAP | 5.121595e-194 | 3.117259e-190 | 5.045707 | 14.256373 | 97.438286 | 33.030037 | 50.0 | 50.0 |
| 3 | H3F3B | 2.158483e-139 | 2.919468e-136 | 2.287395 | 97.323417 | 99.906847 | 4.881739 | 50.0 | 50.0 |
| 4 | PSMA6 | 9.807033e-158 | 1.705443e-154 | 3.847374 | 22.273150 | 89.287378 | 14.393784 | 50.0 | 50.0 |
We just want to make a volcano plot of the result table. We consider as significant genes with p-value below 0.001 (log p-value of 3) and a log-fold-change below -2 and above 2 for this plot. The dot size is the percentege of cells expressing each gene.
As underexpressed genes we find amongst others CXCL2 (upregulated only when azoospermia is together with inflamation) and ZNRF3 (involved in disorder of sex development). Upregulated are for example CMTM1 (involved in fertility, whose knockout has no effect on it), SPATS1 (involved in sperm development) and DLGAP2 (associated to male infertility)
pseudobulk_volcano(DEG_matrix, logfold_threshold=2, logpval_threshold=3, plot_size=(800,800))Finally, you can save the table and download it, to view very easily in Excel.
DEG_matrix.to_csv('./pseudobulk_markers.csv', sep='\t', index=None)
Wrapping up
You executed the whole analysis to the very end of this notebook!
It has been a pretty long one, but I hope you learnt new things and you will benefit from them in your future scRNA-seq analysis. Remember that the scanpy webpage has a lot of tutorials and very good documentation for all the functions implemented. The universe of available tools for single cell RNA data is growing constantly and is difficult to navigate - I suggest you to try tools that seem interesting, are usable without too many dificulties, and then stick only to those that are really relevant. Fortunately the community revolving around scRNA-seq data analysis is huge and rather helpful and open-source. It is mostly a matter of googling yourself to relevant forums and github repositories to find useful answers to doubts, available tools, and guides.
Do you want to look for more advanced analysis? We have an introduction to single cell RNA sequencing also in R and advanced topics in scRNA-seq analysis. You can find those in our Transcriptomics Sandbox on uCloud (for danish users of uCloud), otherwise the tutorials are all documented in web format at their respective webpages: